
12. Big Data Processing#
Wie wir bereits aus Kapitel 1 wissen, gehören neben dem Volume, der Velocity und der Variety auch innovative Informationsverarbeitungsmethoden zur Definition von Big Data. Hiermit wollen wir uns zum Abschluss beschäftigen.
Die Grundlage für alle großen Berechnungen ist die Parallelität. Es gibt hierzu auch ein berühmtes Zitat der Informatikpionierin Grace Hopper: “In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers.” Mit anderen Worten, große Aufgaben können nur gelöst werden, indem man die Ressourcen von vielen kleineren Einheiten gemeinsam nutzt.
12.1. Parallelisierung#
Im Allgemeinen gibt es drei Ansätze zur Parallelisierung von Berechnungen. Der erste Ansatz ist das Message Passing, bei dem die Aufgaben unabhängig voneinander in einer isolierten Umgebung ausgeführt werden. Wenn zwei Aufgaben kommunizieren möchten, tauschen sie Nachrichten aus. Hierdurch können auch Daten zwischen verschiedenen Aufgaben hin und her kopiert werden. Diese Art der Kommunikation kann sowohl lokal auf einer einzelnen physischen Maschine als auch verteilt in einem Netzwerk genutzt werden.
Der zweite Ansatz ist Shared Memory. Hierbei sind die Umgebungen, in denen die Aufgaben ausgeführt werden, nicht voneinander isoliert. Stattdessen haben sie einen gemeinsamen Adressraum, in dem sie die gleichen Variablen lesen und schreiben können. Die Aufgaben interagieren und kommunizieren durch Veränderungen im geteilten Speicher. Auf einer einzelnen physischen Maschine erlaubt das Betriebssystem die Bereitstellung von geteiltem Speicher. Bei Threads ist dies sogar bereits Bestandteil der Art und Weise, wie Aufgaben erstellt werden. Alle Threads eines Prozesses verwenden den gleichen Speicher, Prozesse, die sich Speicher teilen wollen, müssen diesen explizit anfordern. Geteilter Speicher ist auch in verteilten Systemen möglich, zum Beispiel über Netzwerkspeicher oder ähnliche Lösungen, die aber üblicherweise langsamer sind als ein lokal geteilter Speicher.
Der dritte Ansatz ist Data Parallelism. Ähnlich wie beim Message Passing werden hier die Aufgaben unabhängig voneinander auf verschiedenen Partitionen der Daten ausgeführt. Es gibt jedoch einen wichtigen Unterschied: Die Aufgaben müssen nicht miteinander kommunizieren, da die Berechnungen keine Ergebnisse der anderen Aufgaben benötigen. Das bedeutet auch, dass Daten-Parallelismus nur möglich ist, wenn eine starke Entkopplung der Aufgaben in unabhängige Berechnungen erfolgen kann. Solche Probleme nennt man auch embarrassingly parallel, weil man sie fast schon peinlich einfach parallelisieren kann.
12.2. Verteiltes Rechnen zur Datenanalyse#
Da Big Data zu groß zum Verarbeiten mit einer einzelnen physischen Maschine ist, benötigen wir eine verteilte Umgebung für Berechnungen mit Big Data. Bevor Rechenzentren angefangen haben, sich an die Eigenheiten von Big Data anzupassen, wurden großteils Rechencluster (engl. compute cluster) eingesetzt. Die Architektur eines Rechenclusters entspricht in etwa Fig. 12.1. Es gibt einen Storage Layer mit dem Datenspeicher und einen Compute Layer mit den Rechenknoten, die als Rechencluster fungieren. Jeder Rechenknoten ist eine physische Maschine. Der Datenspeicher muss den Rechenknoten schnell zur Verfügung stehen (Latenz, Durchsatz oder beides), benötigt jedoch nicht viel Rechenkraft. Üblicherweise ist dieser Speicher über ein Storage Area Network (SAN) realisiert. Die Rechenknoten sind für Rechenkraft durch CPUs (und evtl. GPUs) und Arbeitsspeicher optimiert. Lokaler Speicher ist nebensächlich und wird häufig nur für die Installation des Betriebssystems und von Programmbibliotheken benutzt sowie eventuell für das Speichern von Zwischenergebnissen. Nutzer übermitteln Jobs an eine Job Queue, die ausgeführt werden, wenn die benötigten Ressourcen zur Verfügung stehen. Daten, die analysiert werden sollen, müssen in einer Datenbank oder dem SAN gespeichert werden, sodass die Rechenknoten Zugriff haben.
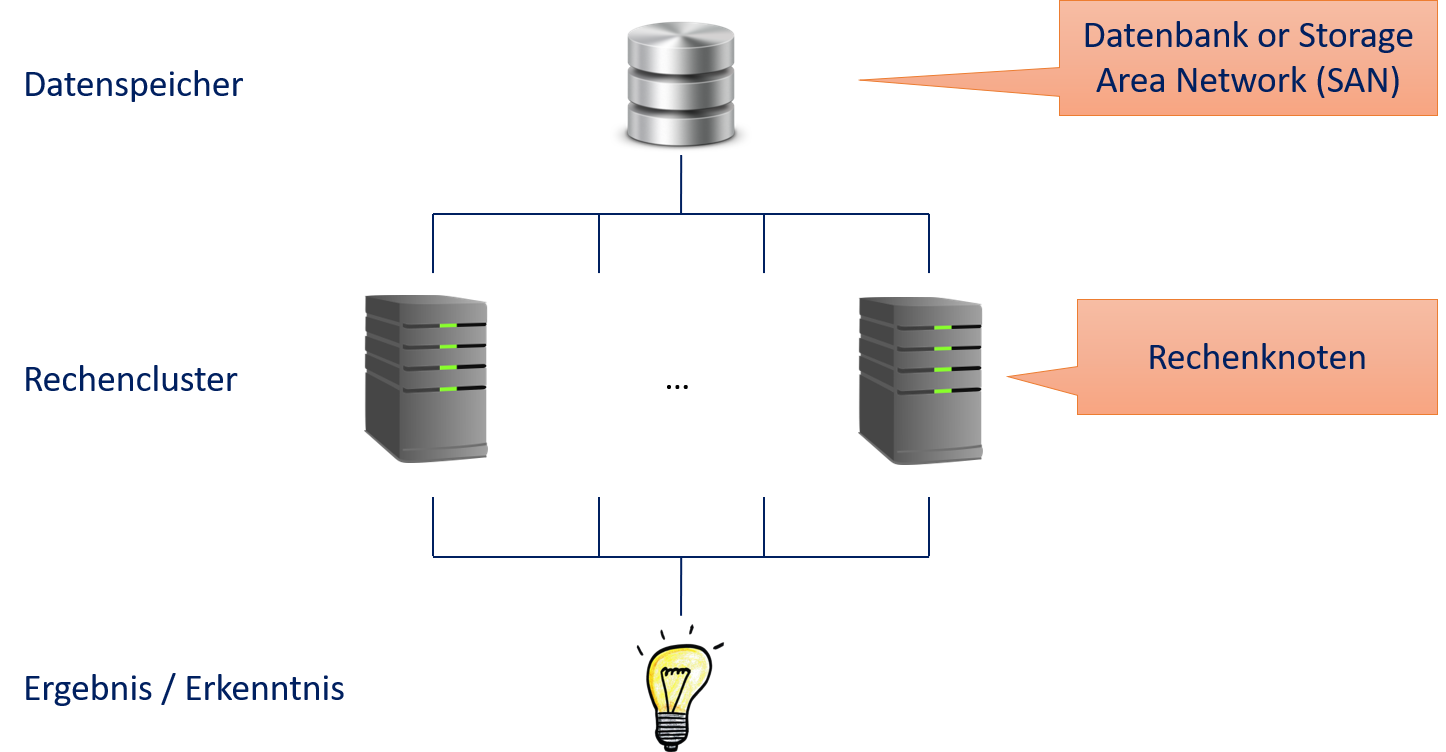
Fig. 12.1 Übliche Architektur eines Rechenclusters#
All drei Ansätze zur Parallelisierung können in einem solchen Rechencluster umgesetzt werden. Keiner der Ansätze ist jedoch dazu geeignet mit Big Data zu arbeiten. Fig. 12.2 zeigt den Bottleneck, der zu Skallierungsproblemen mit Message Passing und Shared Memory führt. Da unklar ist, welche Daten benötigt werden, müssen im schlimmsten Fall alle Daten bei allen Compute Nodes zur Verfügung stehen. Während das bei kleinen Datensätzen kein Problem ist, skaliert dies nicht für große Datensätze, da der Transport der Daten über das Netzwerk zum Bottleneck wird. Hinzu kommt noch die Kommunikation zwischen den Aufgaben, die auf verschiedenen Compute Nodes berechnet werden.
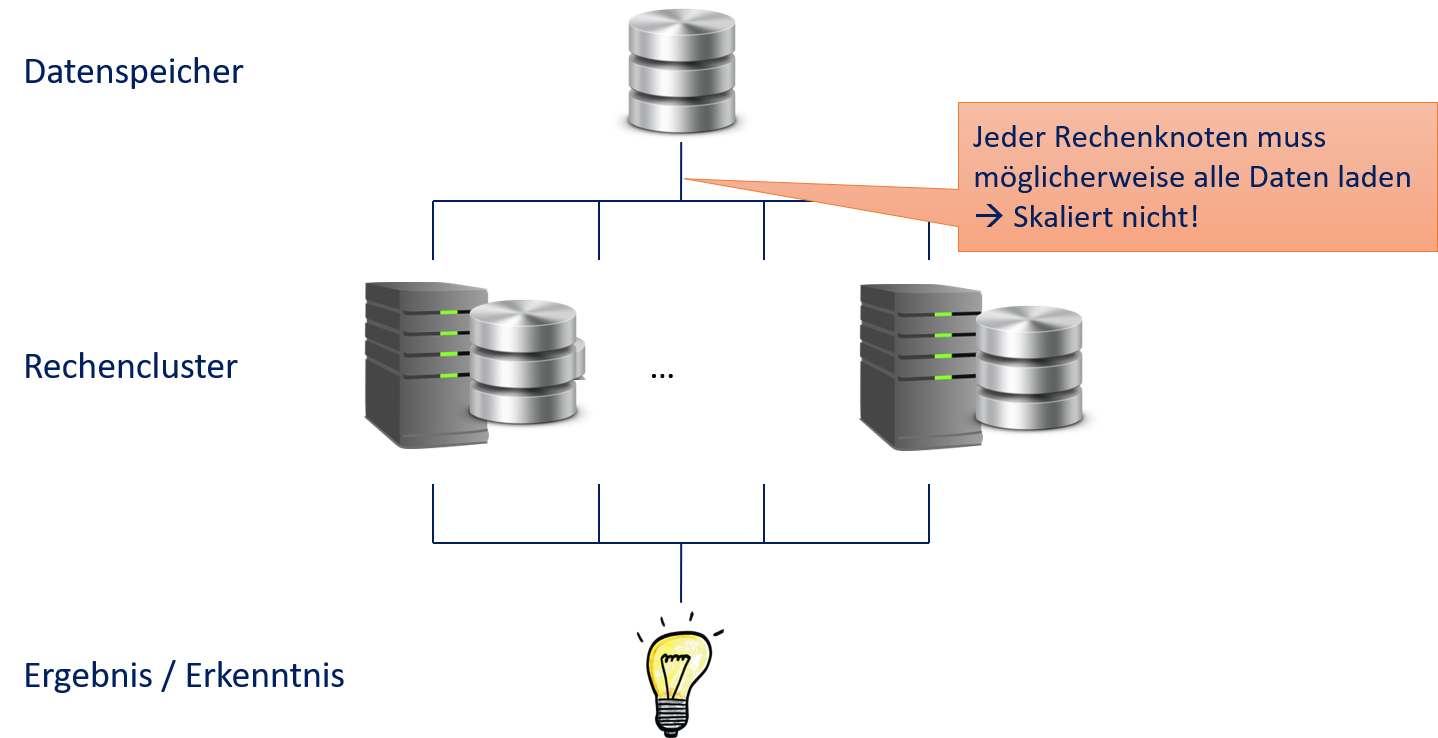
Fig. 12.2 Rechencluster mit Message Passing und Shared Memory#
Daten-Parallelismus ist etwas besser für große Datenmengen geeignet, wie man in Fig. 12.3 sieht. Hier bekommt jeder Rechenknoten nur die Partition der Daten, auf der gerechnet wird. Es müssen also nicht alle Daten, sondern nur ein kleinerer Teil geladen werden. Dennoch müssen alle Daten zu einem Rechenknoten übertragen werden. Der Gewinn ist also nur, dass die Daten nicht mehrfach übertragen werden müssen. Daher kann man mit Daten-Parallelismus zwar größere Datenmengen parallelisieren, aber auch hier wird das Datenvolumen irgendwann zu groß, um über das Netzwerk übertragen zu werden.
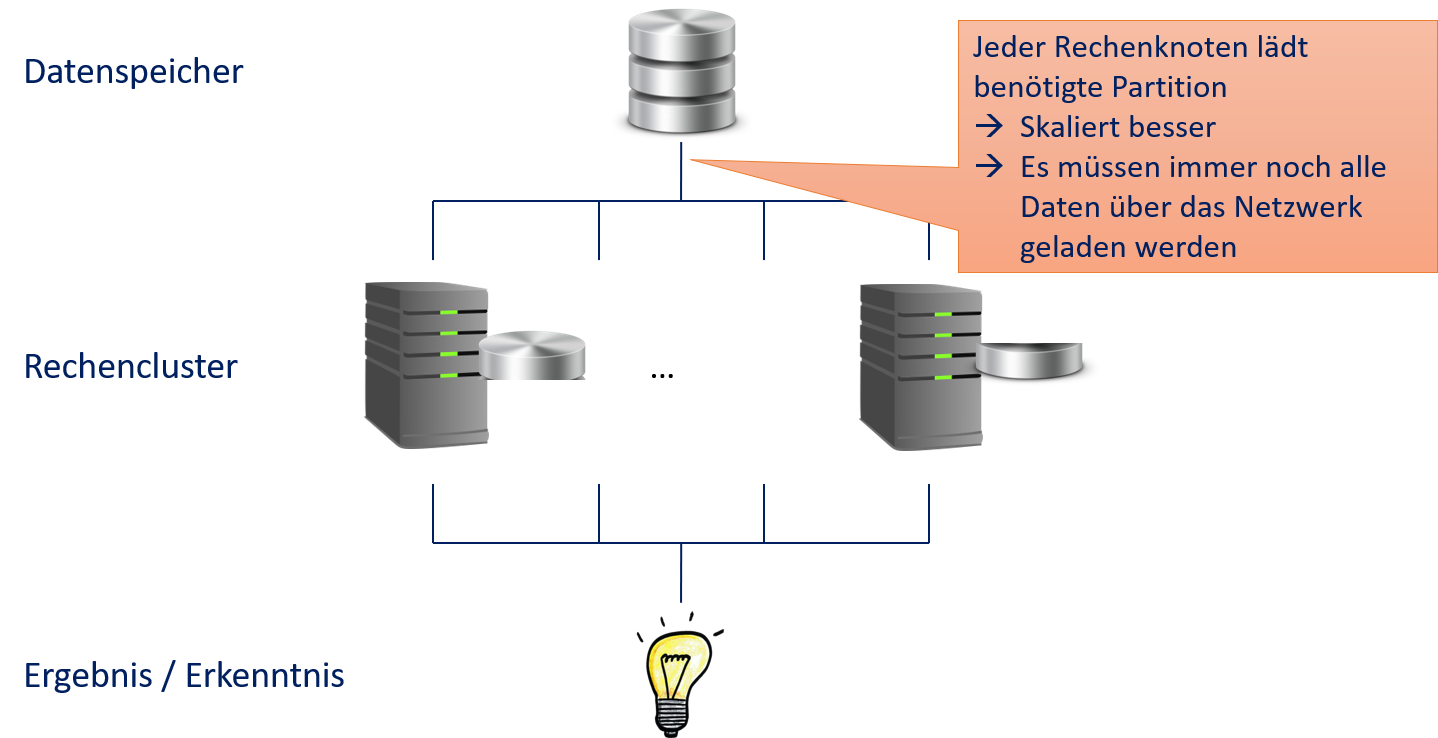
Fig. 12.3 Rechencluster mit Daten-Parallelismus#
12.3. Datenlokalität#
Das fundamentale Problem von traditionellen Recheninfrastrukturen ist also, dass die Daten über das Netzwerk angebunden sind, weshalb wir eine innovative Informationsverarbeitungsmethode benötigen. Die Lösung liegt auf der Hand: Wenn das Problem das Kopieren der Daten über das Netzwerk ist, brauchen wir eine Architektur, bei der die Daten nicht kopiert werden müssen. Wenn die Daten nicht mehr kopiert werden müssen, spricht man auch von Datenlokalität. Hierzu bricht man einfach mit der Trennung des Storage Layer vom Compute Layer: Alle Knoten sind sowohl Datenspeicher als auch Rechenknoten. Das Ergebnis sieht man in Fig. 12.4: einen Rechencluster mit integriertem verteiltem Speicher.
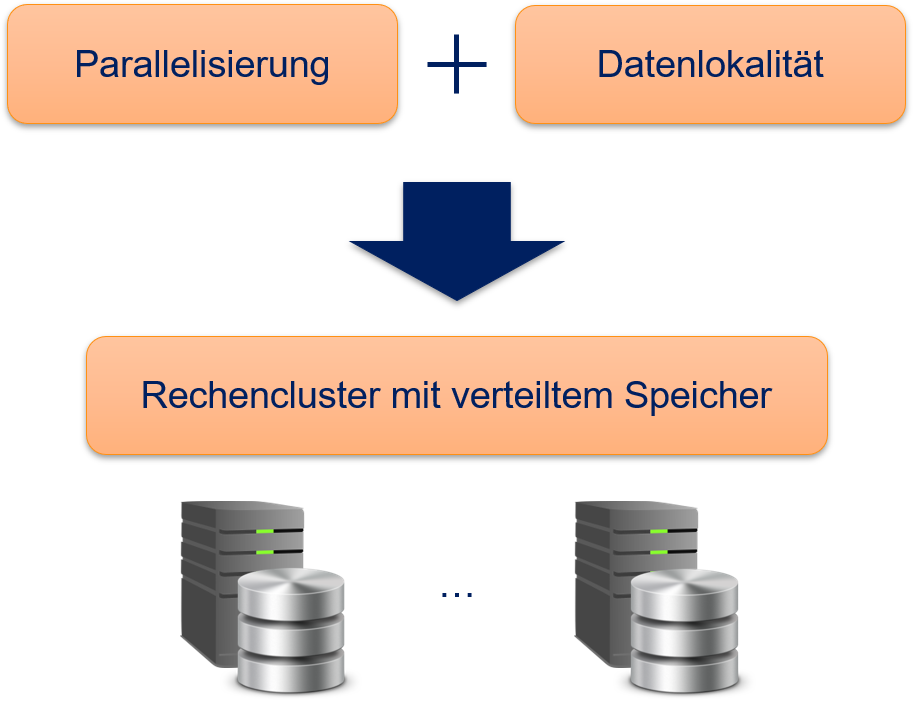
Fig. 12.4 Datenlokalität für Big-Data-Infrastrukturen#
Im Folgenden erklären wir, wie man diese Konzepte in der Praxis umsetzt. Wir besprechen MapReduce als Programmiermodell und betrachten, wie dies von Apache Hadoop und Apache Spark umgesetzt wird, um verteiltes Rechnen mit Big Data zu ermöglichen.
12.4. MapReduce#
Bei MapReduce handelt es sich um ein Programmiermodell, dass Daten-Parallelismus ermöglicht, um den Entwurf von Algorithmen für Berechnungen mit Big Data zu vereinfachen. Vorgestellt wurde MapReduce bereits 2004 in einer Publikation von Google [1]. Die Grundidee ist, dass Berechnungen durch zwei Funktionen ausgedrückt werden: map und reduce. Beide Funktionen arbeiten mit Key-Value-Paaren. Die map-Funktionen sind ideal für die datenparallele Berechnung innerhalb von Algorithmen, mit reduce werden Ergebnisse aggregiert. Das Konzept von map und reduce existiert auch unabhängig von MapReduce als allgemeines Konzept, das man in vielen funktionalen Programmiersprachen wiederfindet. Damit MapReduce für Big Data geeignet ist, gibt es noch eine dritte Funktion, die man als shuffle bezeichnet. Die Aufgabe von shuffle besteht darin, die Zwischenergebnisse von Algorith-men zu arrangieren, sodass die effiziente Kommunikation zwischen map- und reduce-Funktionen gewährleistet ist. Fig. 12.5 fasst die Arbeitsweise von MapReduce zusammen.
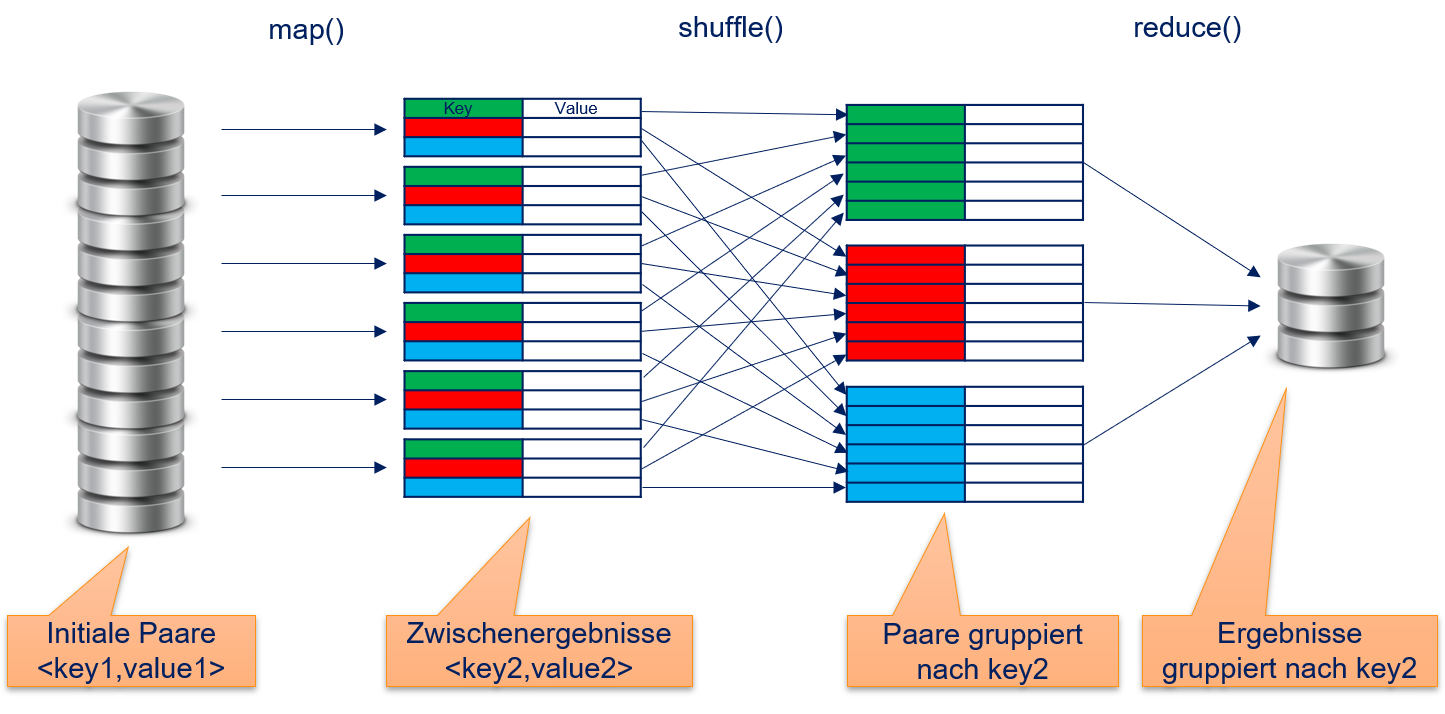
Fig. 12.5 Übersicht des Ablaufs bei MapReduce.#
12.4.1. map()#
Die map-Funktion bekommt als Eingabe die initialen Key-Value-Paare, die analysiert werden sollen. Diese werden zum Beispiel aus einem verteilten Speicher gelesen und könnten auch das Ergebnis einer bereits erfolgten Berechnung mit MapReduce sein. Die map-Funktion berechnet für jedes einzelne Key-Value-Paar ein von allen anderen Paaren unabhängiges Ergebnis. Das Ergebnis sind neue Key-Value-Paare. Die map-Funktion ist also definiert als
wobei \(f_{map}\) eine User-Defined Function (UDF) ist, also eine Funktion, die vom Benutzer an das MapReduce-Framework zur Berechnung des Ergebnisses für ein Key-Value-Paar übergeben wird. Es hängt von der UDF \(f_{map}\) ab, ob die Schlüssel der Ausgaben die gleichen sind wie bei den Eingaben oder ob neue Schlüssel berechnet werden. Im Allgemeinen sind beliebige Typen für die Schlüssel und Werte der Key-Value-Paare möglich. Dies kann aber auch von der Implementierung in einem MapReduce-Framework eingeschränkt werden. Die ursprüngliche MapReduce-Implementierung von Google hat zum Beispiel nur Strings erlaubt, sodass die Benutzer alle anderen Datentypen in Strings konvertieren mussten.
12.4.2. shuffle()#
Die Key-Value-Paare, die von der map-Funktion berechnet werden, werden durch die shuffle-Funktion so organisiert, dass sie durch den Schlüssel gruppiert sind. Es gilt also
wodurch wir eine Liste von Werten pro Schlüssel erhalten. Häufig werden diese Daten auch noch nach dem Schlüssel sortiert, da dies die Effizienz der folgenden Aufgaben erhöhen kann. Die shuffle-Operation ist in der Regel nicht für den Benutzer sichtbar und wird im Hintergrund vom MapReduce-Framework ausgeführt.
12.4.3. reduce()#
Die reduce-Funktion berechnet basierend auf allen Werten für einen Schlüssel ein einziges Ergebnis pro Schlüssel. Die reduce-Funktion ist also definiert als
wobei \(f_{reduce}\) eine UDF ist. Die UDF \(f_{reduce}\) reduziert also alle Werte eines Schlüssels zu einem aggregierten Wert. Ähnlich wie bei der map-Funktion sind die Datentypen im Allgemeinen nicht beschränkt, können aber von der Implementierung eingeschränkt sein. Je nach Aufgabenstellung könnten die Ausgaben Key-Value-Paare für weitere MapReduce-Berechnungen sein oder auch Endergebnisse der Algorithmen.
12.4.4. Worthäufigkeiten mit MapReduce#
Das Konzept von MapReduce ist relativ abstrakt, wenn man es nicht bereits aus der funktionalen Programmierung kennt und gewohnt ist. Wie MapReduce funktioniert, kann man sich aber gut an einem Beispiel veranschaulichen. Das “Hello World” von MapReduce ist das Zählen der Häufigkeit von Wörtern im Text. Das Schöne an diesem Beispiel ist, dass es auch praxisrelevant ist, zum Beispiel für die Erstellung eines Bag-of-Words (siehe Kapitel 10). Wir benutzen den folgenden Text als Beispiel:
Wie ist Ihr Name?
Mein Name ist Bond, James Bond.
Unsere Daten sind als Textdatei mit einer Zeile pro Satz gespeichert. Unsere initialen Key-Value-Paare haben die Zeilennummer als Schlüssel und den Text der Zeile als Wert.
<1, "Wie ist Ihr Name?">
<2, "Mein Name ist Bond, James Bond.">
Die map-Funktion ist so definiert, dass sie ein Paar der Form <Wort, 1> für jedes Wort der Eingabe ausgibt, wobei Satzzeichen ignoriert werden und alles kleingeschrieben wird. Wenn wir dies auf die initialen Paare anwenden, bekommen wir also zehn Paare, für jedes Wort im Text eines:
<"wie", 1>
<"ist", 1>
<"ihr", 1>
<"name", 1>
<"mein", 1>
<"name", 1>
<"ist", 1>
<"bond", 1>
<"james", 1>
<"bond", 1>
Die shuffle-Funktion gruppiert diese Daten jetzt nach ihrem Schlüssel und arrangiert die Werte als Listen.
<"bond", list(1, 1)>
<"ist", list(1, 1)>
<"james", list(1)>
<"name", list(1, 1)>
<"mein", list(1)>
<"wie", list(1)>
<"ihr", list(1)>
Zuletzt erzeugt die reduce-Funktion als Ausgabe eine Zeile pro Schlüssel mit der Worthäufigkeit des jeweiligen Schlüssels.
bond 2
ist 2
james 1
name 2
mein 1
wie 1
ihr 1
12.4.5. Parallelisierung#
Das Design von MapReduce erlaubt es uns, jeden Schritt zu parallelisieren. Die Eingaben können parallelisiert gelesen werden, sofern dies vom Speicherformat zugelassen wird. Dies ist zum Beispiel der Fall, wenn es mehrere Textdateien gibt, sodass jede Datei 1000 Zeilen enthält. Die Performanz dieser Parallelisierung ist jedoch durch die Geschwindigkeit des Speichermediums begrenzt und in der Regel nur sinnvoll, wenn die Daten verteilt auf mehreren physischen Maschinen gespeichert sind.
Da bei der map-Funktion die Berechnung für alle Key-Value-Paare unabhängig ist, ist die Parallelisierung trivial. Es ist theoretisch möglich, das Ergebnis für alle Key-Value-Paare parallel zu berechnen.
Die shuffle-Funktion kann starten, sobald das erste Key-Value-Paar von der map-Funktion berechnet wurde. Hierdurch lassen sich die Wartezeiten reduzie-ren, da shuffle bereits im Hintergrund der map-Funktionen arbeiten kann und daher häufig gleichzeitig mit map fertig wird.
Die reduce-Funktion kann für jeden Schlüssel unabhängig berechnet werden und somit auch parallelisiert werden. Der Grad der Parallelisierung hängt somit lediglich von der Anzahl der einzigartigen Schlüssel ab, die von map berechnet werden. Hinzu kommt, dass reduce schon starten kann, sobald alle Ergebnisse für einen Schlüssel zur Verfügung stehen. Dies ist auch der Grund, warum Sortieren bei shuffle sinnvoll sein kann: Wenn die Ergebnisse bei reduce sortiert ankommen, kann reduce die Verarbeitung der Daten für einen Schlüssel starten, sobald die Daten für den nächsten Schlüssel eintreffen.
12.5. Apache Hadoop#
Apache Hadoop [2] ist eine Open-Source-Implementierung von MapReduce. Für viele Jahre war Hadoop die Standardlösung für MapReduce-Anwendungen. Auch wenn die Relevanz von Hadoop im Laufe der Jahre abgenommen hat, gibt es immer noch viele Anwendungen, die auf Hadoop basieren, und es wird von allen großen Cloud-Dienstleistern als Service zur Verfügung gestellt. Hinzu kommt, dass Hadoop sehr gut geeignet ist, um die technischen Anforderungen an ein MapReduce-Framework zu demonstrieren.
Hadoop 2.0 implementiert MapReduce in einer Architektur mit drei Schichten, die in Fig. 12.6 dargestellt ist. Die unterste Schicht ist das Hadoop Distributed File System (HDFS), das für das Datenmanagement verantwortlich ist. Hierauf baut Yet Another Resource Negotiator (YARN) auf, um die Rechenressourcen zu verwalten. Anwendungen für die Datenverarbeitung setzen auf YARN auf und liegen in der dritten und obersten Schicht von Hadoop. Diese Anwendungen kann man zum Beispiel mit dem MapReduce-Framework von Hadoop umsetzen. Aufgrund des Erfolgs von Hadoop, insbesondere von HDFS und YARN, gibt es aber noch viele weitere Technologien zur Datenverarbeitung, die darauf aufbauen, wie zum Beispiel Apache Spark, das wir in diesem Kapitel auch noch betrachten .
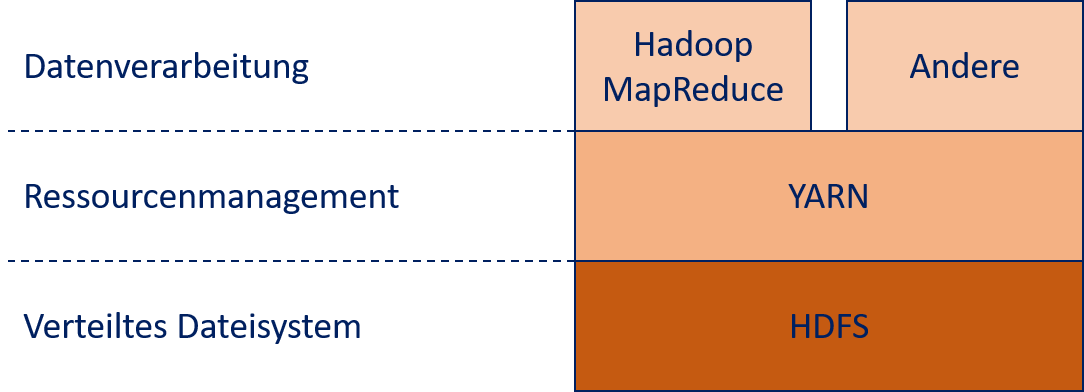
Fig. 12.6 Architektur von Apache Hadoop 2.0#
12.5.1. HDFS#
Das HDFS ist die Kernkomponente von Hadoop. Alle Daten, die analysiert werden sollen, müssen im HDFS gespeichert sein. HDFS wurde für die Verarbeitung von Big Data entwickelt und verhält sich deshalb in einigen wichtigen Aspekten anders als die im Alltag verwendeten Dateisysteme wie NTFS, ext3 oder xfs.
HDFS ist auf den Durchsatz optimiert und hat im Gegenzug eine relativ hohe Latenz. Dies bedeutet, dass das Laden und Speichern von großen Datenmengen schnell ist, es aber eventuell etwas dauert, bis diese Operationen starten.
HDFS unterstützt extrem große Dateien. Die Dateigröße ist nur durch die Größe des verteilten Speichers begrenzt, was bedeutet, dass Dateien größer sein können als der Speicher einer physischen Maschine.
HDFS wurde für datenlokale Berechnungen entwickelt mit dem Ziel, den Austausch von Daten zwischen physischen Maschinen zu minimieren.
Da Hardwareausfälle und Softwareprobleme bei einer großen Anzahl von physischen Maschinen nicht die Ausnahmen sind, sondern alltäglich, wurde HDFS robust entwickelt, sodass es auch im Fall von Hardwareausfällen keinen Datenverlust gibt und Berechnungen weiterhin möglich sind.
Um diese Designziele zu erreichen, verwendet HDFS ein Master/Worker-Paradigma mit einem NameNode der die DataNodes verwaltet. Fig. 12.7 zeigt die Aufgaben des NameNode und der DataNodes. Clients können auf das HDFS über den NameNode zugreifen. Die Dateisystemoperationen, wie Erstellen, Löschen und Kopieren von Dateien, werden aus Nutzersicht daher über den NameNode durchgeführt. Bei der Erstellung werden Dateien in Blöcke unterteilt. Die Blöcke werden entsprechend der Konfiguration des HDFS repliziert, das heißt, nicht nur auf einem DataNode gespeichert, sondern auf mehreren. Dies ist eine wesentliche Komponente, um den Datenverlust oder Systemausfall bei Hardwarefehlern zu vermeiden. Wie die Blöcke auf den DataNodes erstellt, gelöscht und repliziert werden, wird vom NameNode organisiert. Damit das HDFS nicht komplett ausfällt, wenn es ein Problem mit dem NameNode gibt, ist auch ein sekundärer NameNode vorgesehen, der im Fehlerfall die Aufgaben des primären NameNode übernehmen kann .
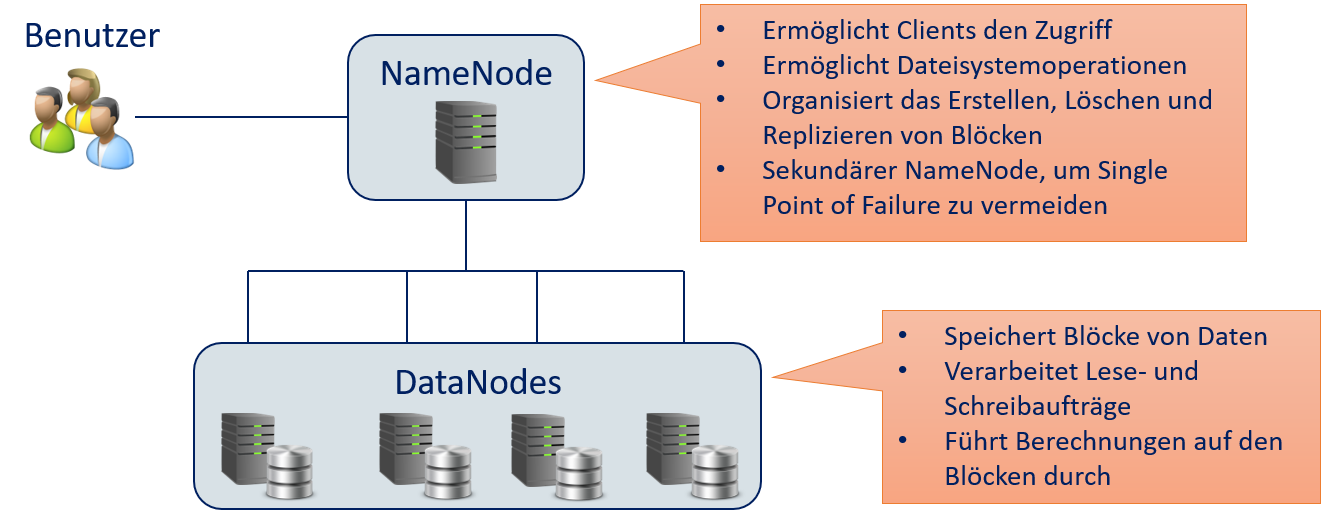
Fig. 12.7 NameNode und DataNodes des HDFS#
Obwohl Benutzer nur über den NameNode auf das HDFS zugreifen, werden die eigentlichen Daten nie über den NameNode geleitet, sondern direkt vom Nutzer zu den DataNodes. Andernfalls wäre der NameNode ein Bottleneck. Fig. 12.8 veranschaulicht, wie Daten vom Benutzer in das HDFS gelangen.
Der Benutzer kontaktiert den NameNode und beantragt, eine Datei zu schreiben.
Der NameNode beantwortet die Anfrage mit einem Datenstrom, den der Benutzer zum Schreiben verwenden kann. Aus der Nutzerperspektive sieht dies wie eine normale Dateioperation aus, ähnlich wie zum Beispiel
FileOutputStreamin Java,std::ofstreamin C++ undopenin Python.Der Benutzer schreibt den Inhalt der Datei in den Datenstrom. Die NameNode hat den Datenstrom so konfiguriert, dass er weiß, wie Blöcke erstellt werden sollen und wo die Daten hin übermittelt werden müssen. Die Daten werden blockweise direkt an die DataNodes geschickt.
Der DataNode empfängt den Block, speichert ihn aber nicht unbedingt selbst. Stattdessen wird der Block möglicherweise an andere DataNodes zum Speichern weitergeleitet. Jeder Block wird nach Möglichkeit bei einem anderen DataNode gespeichert, sodass jeder DataNode möglichst wenig Blöcke der gleichen Datei speichert. Außerdem wird jeder Block auf mehreren DataNodes gespeichert, abhängig vom Replication Level.
Wenn ein DataNode einen Block speichert, wird dies bei dem DataNode, der die Daten empfängt, bestätigt.
Sobald alle Replikationen eines Blocks gespeichert sind, beginnt der Datenstrom automatisch mit dem Schreiben des nächsten Blocks (Schritt 3), bis alle Blöcke geschrieben sind. Dies geschieht automatisch im Hintergrund und ist für den Benutzer nicht transparent.
Sobald der Datenstrom alle Daten verarbeitet hat, informiert der Benutzer den NameNode, dass die Schreiboperation beendet ist und der Datenstrom geschlossen werden kann .
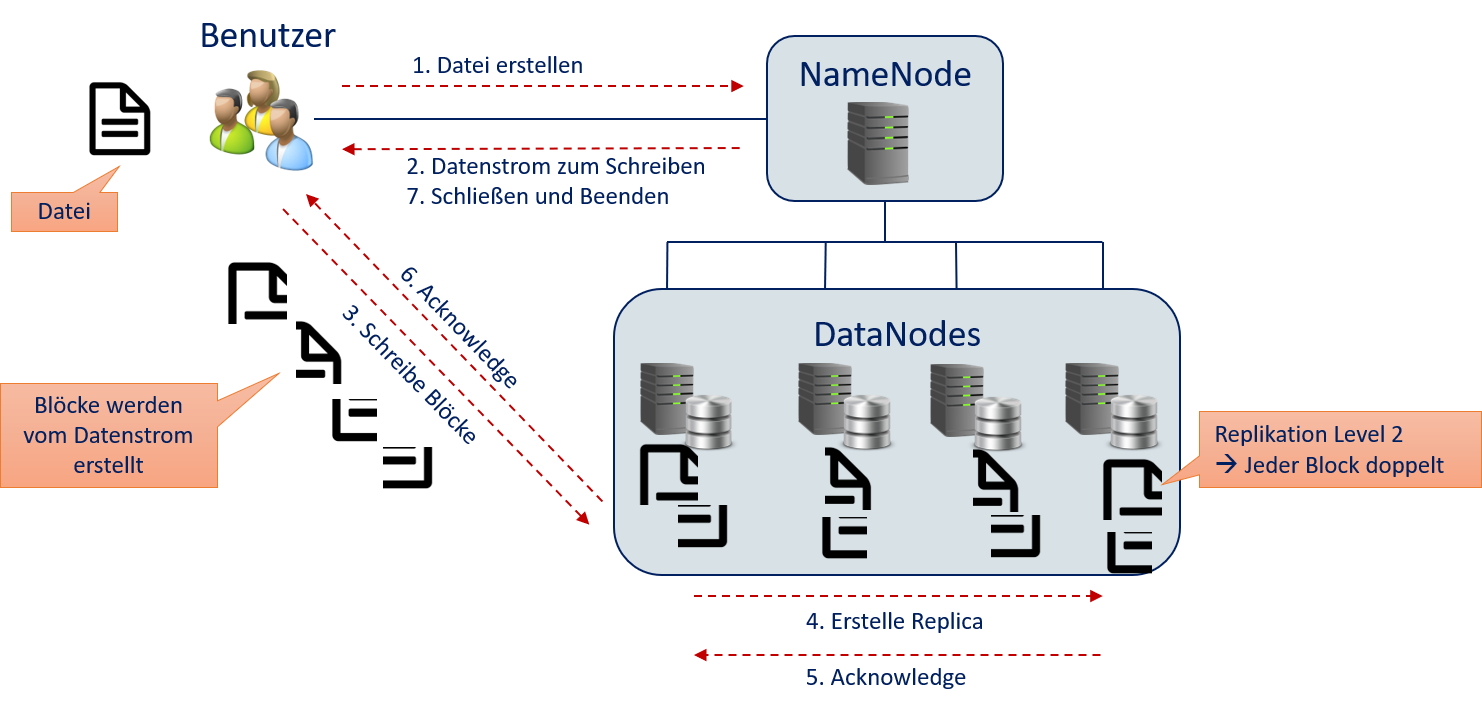
Fig. 12.8 Der Weg der Daten vom Benutzer in das HDFS#
12.5.2. YARN#
YARN wurde entwickelt, um Hadoop-Anwendungen die benötigten Ressourcen für Berechnungen zur Verfügung zu stellen, und zwar so, dass die Berechnungen nach Möglichkeit lokal am Speicherort der Daten im HDFS durchgeführt werden. Wie das HDFS, setzt auch YARN auf ein Master/Worker-Paradigma, bei dem ein Resource Manager die NodeManager verwaltet. Fig. 12.9 zeigt die Aufgaben dieser Komponenten. Der Resource Manager fungiert als Scheduler und stellt auf Anfrage die benötigten Rechenressourcen zur Verfügung. Die NodeManager sind eine auf den DataNodes laufende Anwendung, die für die lokale Ausführung von Aufgaben verantwortlich ist. Hierdurch wird jeder DataNode zu einem Rechenknoten von Hadoop. Die Aufgaben werden vom Resource Manager so zugeteilt, dass sie nach Möglichkeit von einem NodeManager am Ort, wo die benötigten Daten gespeichert sind, ausgeführt werden. Hierzu braucht der Resource Manager detailliertes Wissen über die Speicherorte der Daten im HDFS, kann dieses Wissen aber benutzen, um datenlokale Berechnungen zu erwirken. Die Aufgaben sind zum Beispiel MapReduce-Anwendungen. YARN kann jedoch auch beliebige andere Anwendungen ausführen und ist nicht auf MapReduce beschränkt .
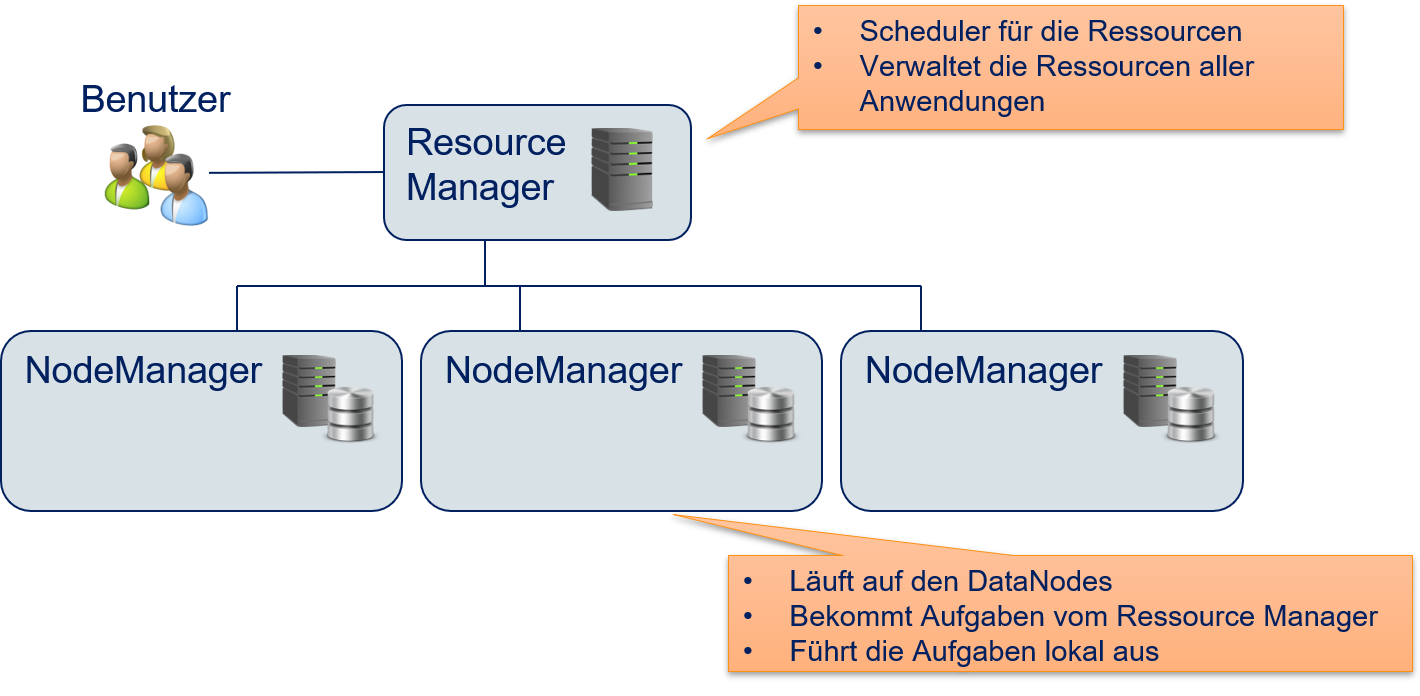
Fig. 12.9 Resource Manager und NodeManager von YARN#
Der Resource Manger sollte die Rechenzeit so zuteilen, dass die Ressourcen (CPU-Kerne, Arbeitsspeicher) effizient genutzt werden. Dies heißt auch, dass jeder NodeManager nur die Aufgaben bekommt, die er mit den lokal verfügbaren Ressourcen bewältigen kann, um eine Überauslastung zu vermeiden. Eine Unterauslastung sollte jedoch ebenfalls vermieden werden: Wenn Jobs auf ihre Ausführung warten und es freie Kapazitäten bei den NodeManagern gibt, sollten diese Jobs diese Kapazitäten auch nutzen können. Der Resource Manager muss also in der Lage sein, mehrere Jobs, möglicherweise von mehreren Benutzern, gleichzeitig durchzuführen und die Ressourcen hierbei fair zu verteilen. Fig. 12.10 beschreibt, wie YARN Ressourcen verwaltet und Anwendungen verteilt ausführt.
Der Benutzer schickt eine Anwendung an den Resource Manager. Der Resource Manager fügt diese Anwendung in der Warteschlange hinzu, bis die benötigten Ressourcen zu Verfügung stehen.
Der Resource Manager allokiert einen Container auf einem der NodeManager und startet den Application Master. Der Application Master ist nicht die Anwendung selbst, sondern ein generisches Programm, das weiß, wie die Anwendung ausgeführt werden soll, also welche Aufgaben durchgeführt werden müssen und welche Ressourcen hierfür benötigt werden.
Der Application Master beantragt die benötigten Ressourcen beim Resource Manager.
Die NodeManager werden vom Resource Manager beauftragt, weitere Container zu allokieren. In unserem Beispiel werden zwei Container benötigt.
Der Resource Manager informiert den Application Master, dass die benötigten Ressourcen zur Verfügung stehen. Dem Application Master wird hierbei auch mitgeteilt, wo sich die Ressourcen befinden und wie auf die Ressourcen zugegriffen werden kann.
Der Application Master führt die Anwendung in den Containern aus. Wenn die Anwendung aus mehreren Aufgaben besteht, wird nur ein Teil der Anwendung ausgeführt und für die weiteren Aufgaben werden neue Ressourcen beantragt. Eventuell konfiguriert der Application Master hierfür die Ausführungsumgebung, zum Beispiel indem Umgebungsvariablen gesetzt werden. In der Regel benutzen die Anwendungen Ressourcen, die auf dem jeweiligen NodeManager lokal zur Verfügung stehen, zum Beispiel installierte Anwendungen, die ausgeführt werden, oder Daten aus dem HDFS .
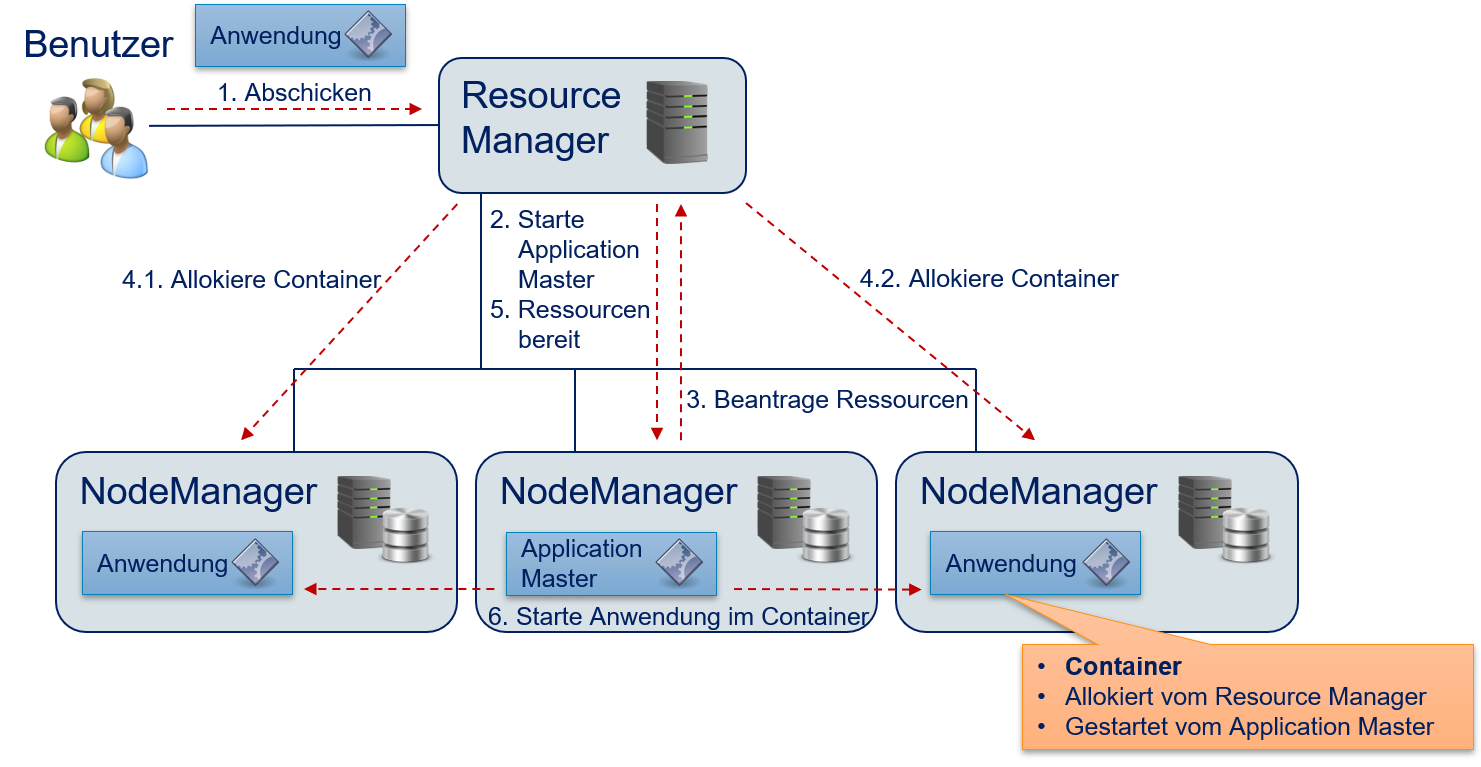
Fig. 12.10 Verteilung von Anwendungen von mit YARN#
Sobald eine Anwendung beendet ist, werden alle Container zerstört und die Ressourcen wieder freigegeben. Auf die Ergebnisse der Ausführung kann man nur über das HDFS zugreifen. Um im dritten Schritt Ressourcen zu beantragen, werden die folgenden Informationen benötigt:
Die Anzahl der benötigten Container
Der erforderliche Arbeitsspeicher und die Anzahl der CPU-Kerne pro Container
Die Priorität der Ressourcenanfrage. Diese Priorität ist nur für die Anwendung gültig und nicht global. Das heißt, dass die Priorität nur wichtig ist, wenn in einer Anwendung mehrere Aufgaben durchgeführt werden müssen, bei denen einige wichtiger sind. Eine hohe Priorität verschafft keinen Vorteil gegenüber anderen Anwendungen, die parallel ausgeführt werden.
Es ist auch möglich, bestimmte Ressourcen namentlich zu identifizieren und direkt zu beantragen. Das könnte zum Beispiel ein bestimmter NameNode sein, aber auch eine topografische Komponente aus einem größeren Cluster, zum Beispiel ein NodeManger der auf einer physischen Maschine in einem bestimmten Rack eines Serverschranks läuft.
12.5.3. MapReduce mit Hadoop#
Es gibt auch ein MapReduce-Framework als Teil von Hadoop, das die Anwendungen mithilfe von YARN ausführt. Die MapReduce-Anwendungen werden vom Benutzer als Sequenz von map/reduce-Funktionen zum Lösen einer Aufgabenstellung definiert. Die Funktionen werden dann von der Java-Anwendung MRAppMaster ausgeführt. Der MRAppMaster definiert einen Application Master, der die Ausführung mithilfe von YARN organisiert, die Ressourcen für die map- und reduce-Aufgaben beantragt und die Funktionen startet. Die Anwendung selbst wird in Java programmiert.
Die map- und reduce-Funktionen werden durch Vererbung definiert. Unter-klassen der Klasse Mapper definieren die map-Funktionen, Unterklassen von Reducer definieren die reduce-Funktionen. Der folgende Quelltext definiert eine map-Funktion für unser Worthäufigkeitsbeispiel. Wir lassen den Boilerplate-Quelltext weg, zum Beispiel zum Importieren von Klassen. Das vollständige Beispiel befindet sich in der offiziellen Hadoop-Dokumentation [3]:
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// text into tokens
StringTokenizer itr = new StringTokenizer(value.toString().toLowerCase());
while (its.hasMoreTokens()) {
// add an output pair <word, 1> for each token
word.set(itr.nextToken());
context.write(word, one);
}
}
}
Der TokenizerMapper erweitert die generische Klasse Mapper mit vier Parametern der Typen Object, Text, Text und IntWritable. Die ersten beiden Parameter definieren die Typen der Eingabepaare, also vom Schlüssel und Wert der Eingaben. Die Eingaben haben demnach Schlüssel vom Typ Object und Werte vom Typ Text. Die letzten beiden Parameter definieren den Typ der Ausgaben. Die map-Funktion berechnet also Key-Value-Paare mit Schlüsseln vom Typ Text und Werten vom Typ IntWritable. Text und IntWritable sind von Hadoop zur Verfügung gestellte Datentypen, die ähnlich zu den Java-Datentypen String und Integer sind. Der Hauptunterschied ist, dass diese aus Effizienzgründen mutable sind, das heißt, dass die Werte der Objekte verändert werden können. Außerdem sind die Hadoop-Datentypen für die Serialisierung optimiert, um den effizienten Austausch von Key-Value-Paaren zwischen map- und reduce-Aufgaben zu gewährleisten.
Die Klasse hat zwei Attribute one und word, die für die Erzeugung der Ausga-ben benutzt werden. Da es sich um Attribute handelt, werden diese nur einmal initialisiert, was die Effizienz erhöht. Die map-Funktion selbst definiert, wie die Ausgaben aus den Eingaben berechnet werden. Als Parameter bekommt die map-Funktion neben dem Eingabepaar aus Key und Value auch noch den context. Dieser Kontext spezifiziert die Hadoop-Ausführungsumgebung und beinhaltet zum Beispiel die Werte von Umgebungsvariablen. Außerdem werden die Ausgaben durch den Aufruf von context.write() in den Kontext geschrieben. Die map-Funktion hat also keinen Rückgabewert. Stattdessen werden die Ergebnisse kontinuierlich in den Kontext geschrieben. Die shuffle-Funktion ist Teil des Kontexts und kann Key-Value-Paare verarbeiten, sobald diese geschrie-ben wurden. Hierdurch kann shuffle nebenläufig zu map arbeiten.
Der folgende Quelltext zeigt die zum Beispiel gehörende reduce-Funktion:
public static class IntSumReader extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
// calculate sum of word counts
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// write result
context.write(key, result);
}
}
Der IntSumReader erweitert die generische Klasse Reducer. Die Parameter beschreiben wie beim TokenizerMapper die Typen der Key-Value-Paare. Wie oben wird das Attribut result aus Effizienzgründen verwendet und die Ergebnisse in den Kontext geschrieben. Der Hauptunterschied zwischen map und reduce ist, dass die reduce-Funktion ein Iterable der Werte übergeben bekommt statt eines einzelnen Wertes. Hierdurch kann reduce auf alle zu einem Schlüssel gehörenden Werte zugreifen.
Zuletzt benötigt eine Hadoop-MapReduce-Anwendung noch eine Klasse, die die Anwendung selbst definiert, in der die Daten sowie die Aufrufe der map- und reduce-Funktionen spezifiziert werden.
public class WordCount {
public static void main(String[] args) throws Exception {
// Hadoop configuration
Configuration conf = new Configuration();
// Create a Job with the name "word count"
Job job = Job.getInstance(conf, "word count");
job.setJahrByClass(WordCount.class);
// set mapper, reducer, and output types
job.setMapperClass(TokenizerMapper.class);
job.setReduczer(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// specify input and output files
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// run job and wait for completion
job.waitForCompletion(true);
}
}
Es handelt sich hierbei um eine normale Java-Anwendung mit einer main-Methode, deren Quelltext großteils selbsterklärend ist. Zuerst wird die Hadoop-Anwendung konfiguriert. Das conf-Objekt beinhaltet unter anderem den Kontext und die MapReduce-Aufgaben. Wir benutzen den Kontext, um den MapReduce-Job zu erstellen. Dann konfigurieren wir den Job. Hierzu definieren wir die Klassen, die die map- und reduce-Funktionen bereitstellen, sowie die Typen der Ausgabe. Anschließend definieren wir, von wo die Daten gelesen und wohin die Ergebnisse geschrieben werden. In der letzten Zeile wird der Job gestartet und die Anwendung wartet auf die Beendigung des Jobs, also auf den Zeitpunkt, an dem die map- und die reduce-Funktionen auf alle Daten angewendet wurden und die Ergebnisse in das Dateisystem geschrieben wurden.
Diese Anwendung können wir jetzt mithilfe von YARN ausführen. Im Folgenden erklären wir die durchgeführten Schritte, die auch in Fig. 12.11 bis Fig. 12.15 dargestellt sind:
Der Benutzer erstellt ein jar-Archiv der MapReduce-Anwendung und schickt dieses an den Resource Manager.
Der Resource Manager startet den
MRAppMasterals Application Master für die Anwendung, um die Ausführung vonWordCount.jarzu orchestrieren.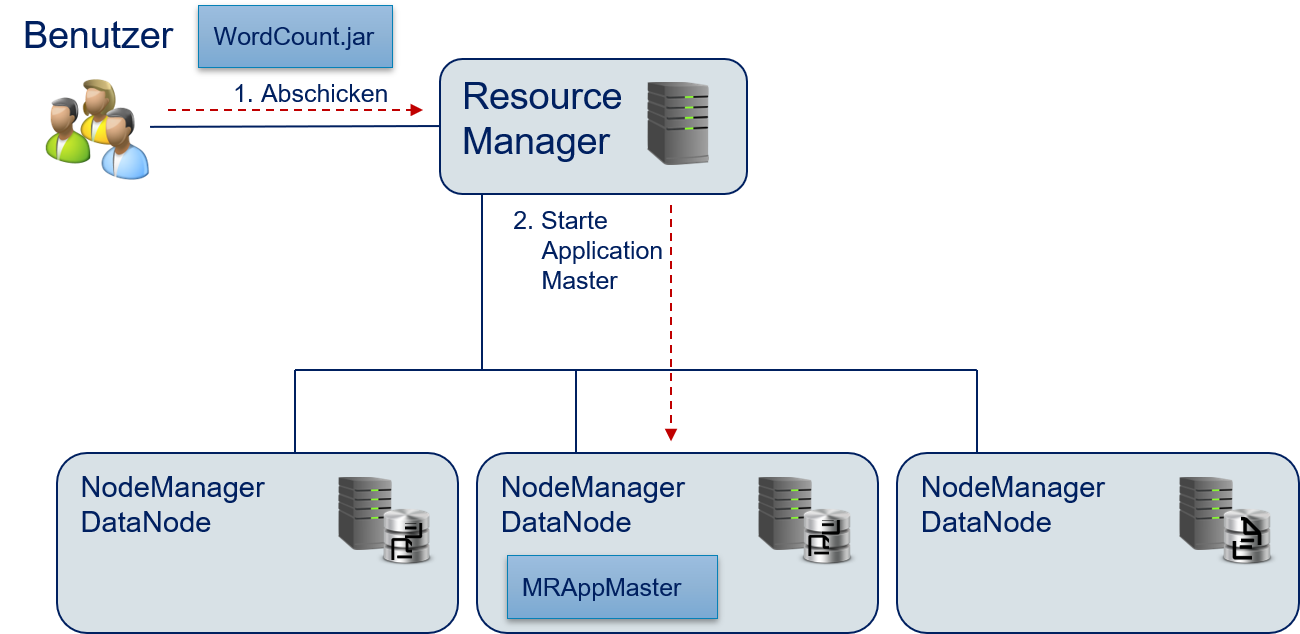
Fig. 12.11 Wörter zählen mit Hadoop: Starten der Anwendung.#
Der
MRAppMasterwertet die Konfiguration der Hadoop-Anwendung inWordCount.jaraus und findet einen Job mit einermap- und einerreduce-Funktion. DerMRAppMasterbeantragt die Ressourcen für diemap-Funktion vom Resource Manager.Der Resource Manager stellt die Ressourcen für die Ausführung von
mapbereit. Hierzu werden zwei Container auf den DataNodes, wo die Daten gespeichert sind, allokiert. Hierdurch müssen die Daten nicht über das Netzwerk übertragen werden.Der Resource Manager sendet die Informationen über die Container an den
MRAppMaster.Der
MRAppMasterführt diemap-Funktion in den Containern aus. Die Daten werden lokal aus dem HDFS gelesen.Die
map-Funktion wurde ausgeführt und die Zwischenergebnisse werden lokal im HDFS abgelegt.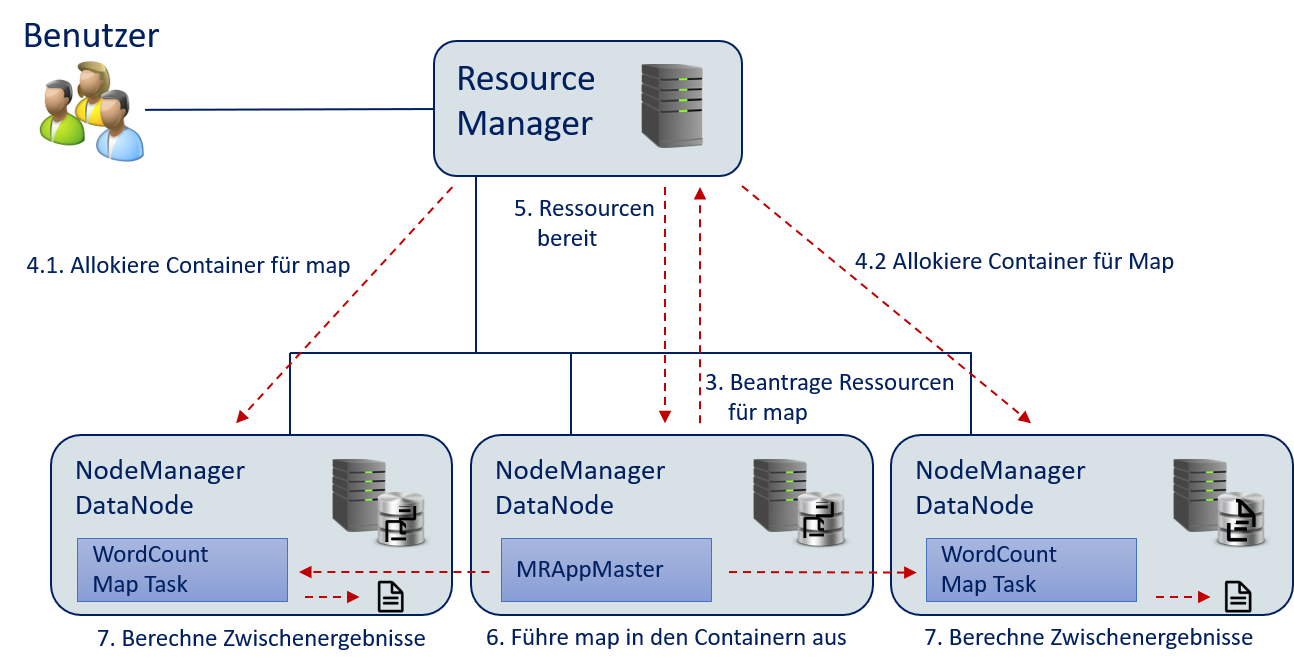
Fig. 12.12 Wörter zählen mit Hadoop: Ausführen von
map.#Der
MRAppMasterinformiert den Resource Manager, dass die Container fürmapnicht mehr benötigt werden.Der Resource Manager zerstört die für
mapallokierten Container und gibt die Ressourcen wieder frei.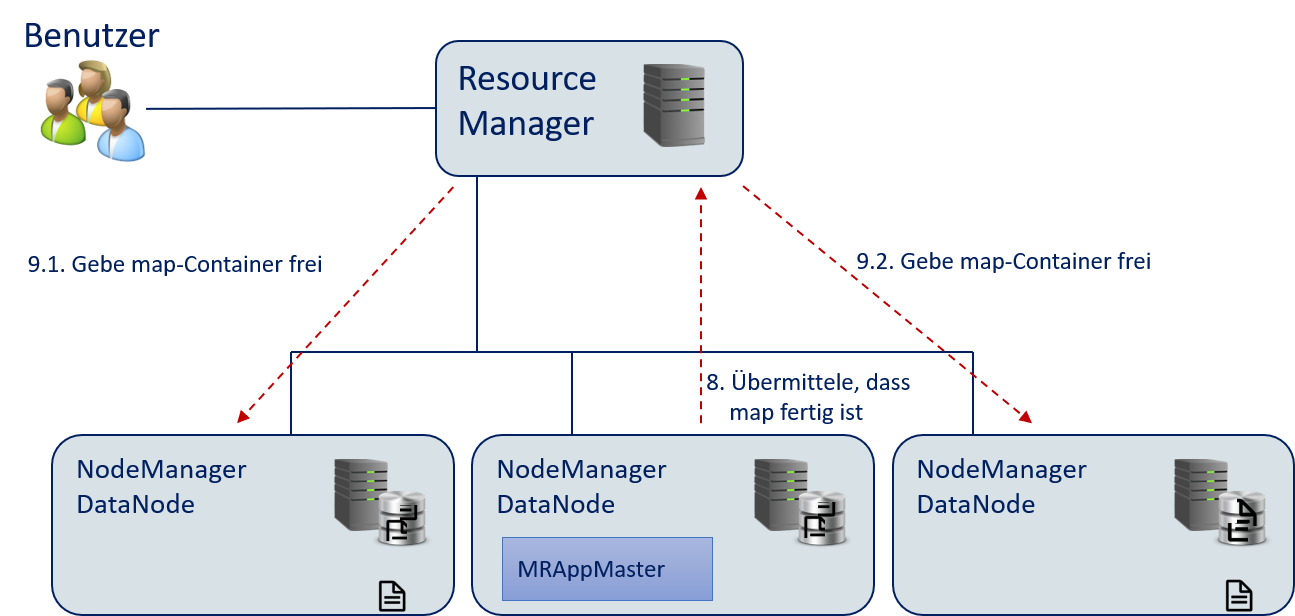
Fig. 12.13 Wörter zählen mit Hadoop: Freigabe der
map-Ressourcen.#Der
MRAppMasterbeantragt die Ressourcen für diereduce-Funktion. Hierfür wird nur ein Container benötigt, da die Ergebnisse aggregiert werden sollen.Der Resource Manager allokiert die Ressourcen für einen Container.
Der Resource Manager sendet die Informationen über den Container an den
MRAppMaster.Der
MRAppMasterführt diereduce-Funktion in dem Container aus.Der
MRAppMastersorgt für die Ausführung vonshufflebei den NodeManagern um die Zwischenergebnisse zu gruppieren und an diereduce-Funktion weiterzuleiten.Die
reduce-Funktion schreibt die Ergebnisse ins HDFS.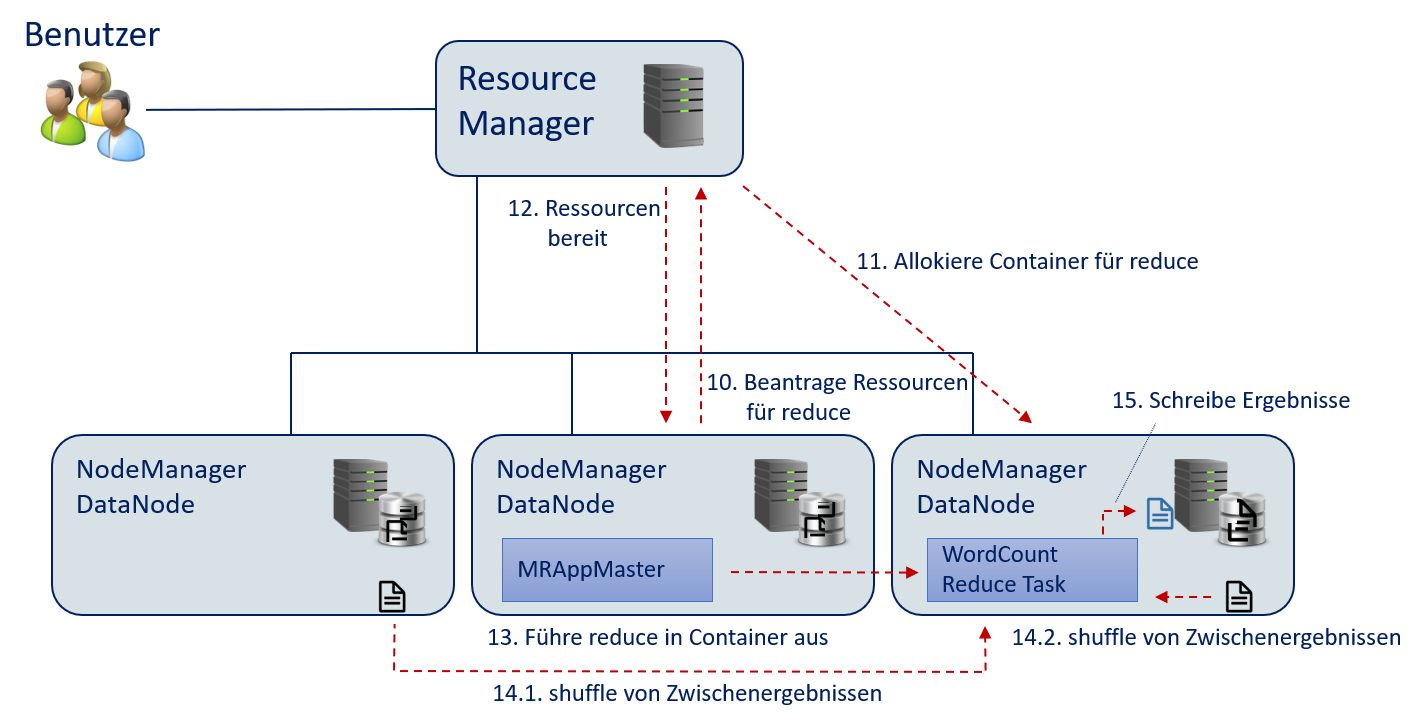
Fig. 12.14 Wörter zählen mit Hadoop: Ausführen von
reduce.#Der
MRAppMasterteilt dem Resource Manager mit, dass die Ausführung aller Aufgaben beendet ist.Der Resource Manager gibt die noch allokierten Ressourcen frei.
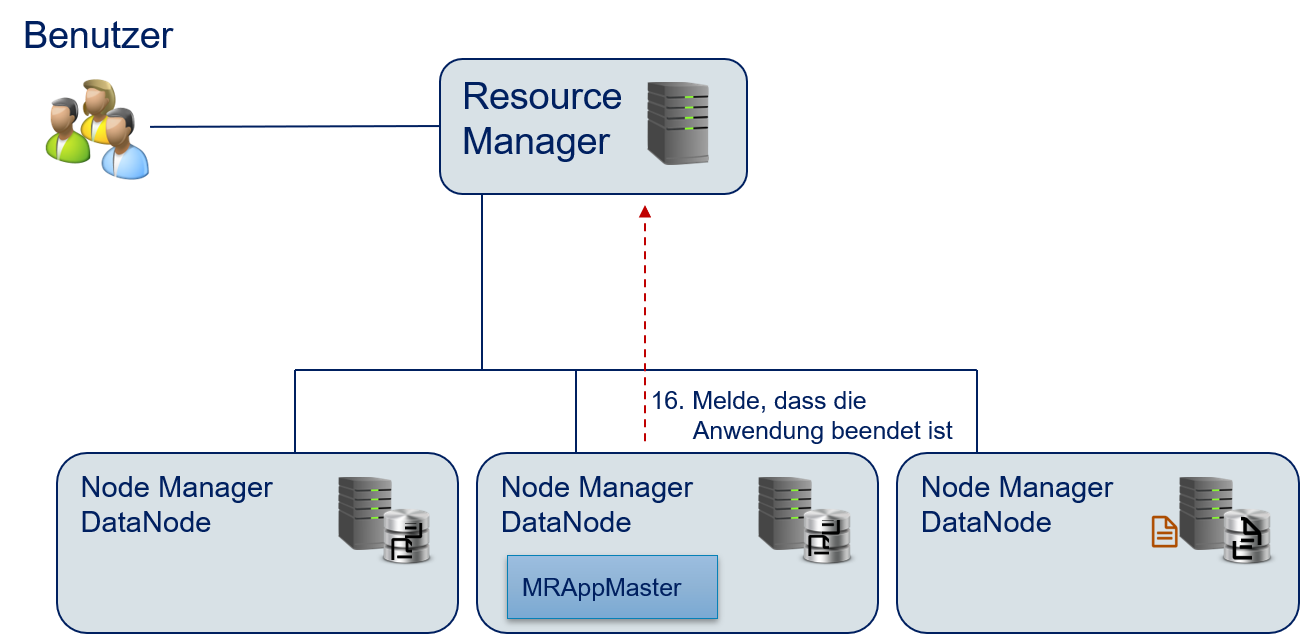
Fig. 12.15 Wörter zählen mit Hadoop: Beenden der Anwendung.#
12.5.4. Streaming Mode#
Als Teil von Hadoop gibt es auch eine Java-Anwendung zur Ausführung von Hadoop im Streaming Mode. Beim Streaming Mode wird die Standardeingabe und die Standardausgabe benutzt, ähnlich wie bei Linux Pipes. Die Daten werden vom HDFS gelesen und an eine beliebige, vom Benutzer definierte Anwendung über den Standardinput weitergeleitet. Die Ergebnisse der Anwendung werden auf die Standardausgabe geschrieben. Hier ist ein Beispiel für eine Python-Anwendung, die die map-Funktion für das Wörterzählen im Streaming Mode definiert:
#!/usr/bin/env python
"""mapper.py"""
import sys
# read from standard input
for line in sys.stdin:
# split line into words
words = line.strip().split()
# create output pairs
for word in words:
# print output pairs to standard output
# key and value are separated by tab (standard for Hadoop)
print('%s\t%s' % (word, 1))
Auf ähnliche Weise können wir auch eine reduce-Funktion definieren.
#!/usr/bin/env python
"""reducer.py"""
from operator import itemgetter
import sys
# init current word and counter as not existing
current_word = None
current_count = 0
word = None
# read from standard input
for line in sys.stdin:
# read output from mapper.py
word, count = line.strip().split('\t', 1)
count = int(count)
# Hadoop shuffle sorts by key
# -> all values with same key are next to each other
if current_word==word:
current_count += count
else:
if current_word:
# write result to standard output
print('%s\t%s' % (current_word, current_count))
# reset counter and update current word
current_count = count
word = word
# output for last word
if current_word==word:
print('%s\t%s' % (current_word, current_count))
Zur Ausführung des Streaming Mode wird die hadoop-streaming.jar-Anwendung, die Bestandteil von Hadoop ist, eingesetzt. Mit dem folgenden Befehl könnten wir mit unseren Python-Anwendungen die Wörter zählen:
hadoop jar hadoop-streaming.jar \
- input myInputDirs \
- output my OutputDir \
- mapper mapper.py \
- reducer reducer.py \
- file mapper.py \
- file reducer.py
Bei hadoop-streaming.jar handelt es sich um eine ganz normale MapReduce-Anwendung für Hadoop, die mit Java wie oben beschrieben definiert ist. Die map-Funktion dieser Anwendung macht aber nichts anderes, als die Eingabepaare auf die Standardeingabe zu schreiben, wo sie dann von mapper.py gelesen werden. Außerdem liest die map-Funktion von der Standardeingabe und schreibt die gelesenen Werte in den Kontext. Analog ist auch die reduce-Funktion bei der hadoop-streaming.jar-Anwendung definiert. Die input- und output-Parameter geben die Speicherorte für die Daten im HDFS an. Die file Parameter werden benötigt, um die Python-Anwendungen auf die NodeManager zu kopieren. Mit dem Streaming Mode kann man beliebige Sprachen und Technologien zur Definition von Hadoop-Anwendungen benutzen.
12.5.5. Weitere Komponenten von Hadoop#
Neben den bisher beschriebenen Kernkomponenten hat Hadoop noch einige weitere wichtige Komponenten. Auch wenn wir diese nicht im Detail diskutieren, wollen hier noch die wichtigsten beiden kurz ansprechen.
Die combine-Funktion ist ähnlich zur reduce-Funktion, läuft jedoch lokal auf den DataNodes bevor die Daten durch shuffle zu anderen Knoten für das reduce übertragen werden. In vielen Anwendungsfällen ist combine identisch zu reduce. Beim Wörterzählen können wir zum Beispiel reduce problemlos mehrfach in Folge ausführen, da wir einfach nur Werte aufsummieren. Ohne combine werden aktuell nur Einsen summiert. Mit einer combine-Funktion werden bereits lokal Worthäufigkeiten berechnet, sodass shuffle für jedes lokal vorkommende Wort nur noch ein Key-Value-Paar mit der Häufigkeit dieses Worts an reduce übertragen muss. Hierdurch kann combine die Daten, die für reduce übertragen werden müssen, erheblich reduzieren. Bei unserem Beispiel müsste man nur ein Paar <bond, 2> statt zwei Paare <bond, 1> übertragen. Je höher der Anteil der Daten, die bereits lokal aggregiert werden können, desto stärker sind die Auswirkungen einer combine-Funktion. Damit man, wie eben beschrie-ben, Funktionen beliebig mehrfach hintereinander ausführen kann, müssen diese Idempotent sein.
Der MapReduce Job History Server bietet Benutzern die Möglichkeit, sich über den Status von Anwendungen zu informieren. Hierzu stellt der Server unter anderem Logdateien der Anwendungsausführung, die Start- und Endzeitpunkte sowie den Zustand der Anwendung bereit, zum Beispiel ob eine Anwendung auf die Ausführung wartet (pending), aktuell ausgeführt wird (running), bereits beendet ist (finished) oder ob die Ausführung fehlgeschlagen ist (failing). Ähnliche Komponenten wie den MapReduce Job History Server gibt es auch in anderen Big-Data-Technologien zur Überwachung von Anwendungen.
12.5.6. Grenzen von Hadoop#
Auch wenn insbesondere das HDFS und YARN von Hadoop immer noch häufig zur Entwicklung von neuen Anwendungen verwendet werden, ist die MapReduce-Implementierung von Hadoop etwas in die Jahre gekommen und hat zwei große Probleme. Das erste Problem ist, dass viele Algorithmen nicht nur aus einer map- und einer reduce-Funktion bestehen, sondern viele solche Operationen benötigen, um das gewünschte Ergebnis zu berechnen. Bei Hadoop muss man die Abhängigkeiten hierbei als Entwickler durch die Erstellung und manuelle Verknüpfung von Job-Objekten definieren. Für mehrere map- und reduce-Jobs braucht man also viele Job-Objekte und man muss für jedes Objekt festlegen, welche Jobs vorher beendet sein müssen, wann auf die Beendigung eines Jobs gewartet werden muss und an welche Jobs Ausgaben weitergeleitet werden müssen. Dies ist aufwendig, fehleranfällig und führt häufig zu einer nicht optimalen Modellierung der Abhängigkeiten.
Das zweite große Problem besteht darin, dass alle Zwischenergebnisse im HDFS gespeichert werden. Das ist kein Problem, wenn die Daten nur ein einziges Mal gelesen und verarbeitet werden müssen. Je mehr Verarbeitungsschritte es aber für die Daten gibt, desto höher wird der Mehraufwand durch das wiederholte Schreiben in das Dateisystem. Es wäre besser, wenn die Daten lokal im Arbeitsspeicher vorgehalten und so einfacher von folgenden Jobs nachgenutzt werden könnten. In der Konsequenz werden insbesondere iterative Algorithmen von Hadoop nicht sehr effizient ausgeführt.
12.6. Apache Spark#
Apache Spark ist eine Big-Data-Technologie und wurde mit dem Ziel entwickelt, die oben beschriebenen Grenzen von Hadoop zu überwinden und In-Memory-Analysen zu ermöglichen sowie die Definition von komplexen Algorithmen zu vereinfachen.
12.6.1. Architektur#
Im Gegensatz zu Hadoop liefert Spark einen mächtigen Softwarestack zur Datenverarbeitung. Hier stellt Hadoop nur grundlegende Funktionen bereit, mit denen die Benutzer selbst Funktionalität definieren können. Die Kernkomponenten von Spark zur Verarbeitung von Big Data sind in Fig. 12.16 abgebildet. Auf der untersten Ebene stellt Apache Spark die benötigten Funktionen zur Datenverarbeitung bereit. Darauf aufbauend gibt es vier Bibliotheken, um die Entwicklung von Anwendungen zu unterstützen.
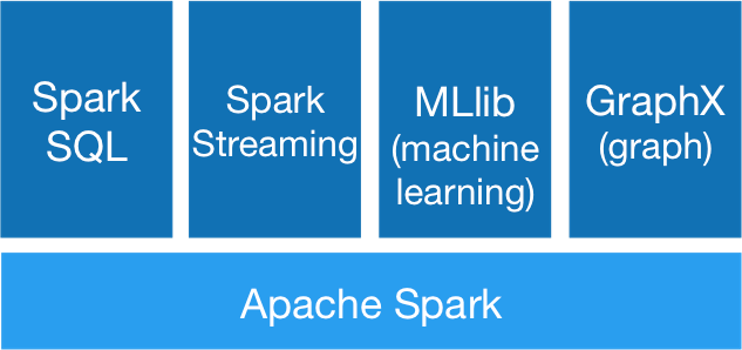
Fig. 12.16 Architektur von Apache Spark#
Spark SQL unterstützt an SQL angelehnte Anfragen an die Daten, die für die Analyse genutzt werden sollen. Da SQL weit verbreitet ist, hilft Spark SQL beim Einstieg in die Spark-Entwicklung erheblich. Spark Streaming unterstützt das Arbeiten mit Streaming-Daten. Hierdurch kann Spark mit kontinuierlichen Datenströmen umgehen und diese verarbeiten. Dies ist mit Hadoop nicht möglich. Mit MLlib und GraphX stellt Spark auch zwei Bibliotheken mit vordefinierten Algorithmen zur Datenverarbeitung zur Verfügung. MLlib beinhaltet viele Algorithmen, die wir in den letzten Kapiteln kennengelernt haben. GraphX beinhaltet die benötigten Hilfsmittel zur Analyse von Graphen, um zum Beispiel soziale Netzwerke zu analysieren.
12.6.2. Datenstrukturen#
Die von Spark verwendeten Datenstrukturen sind für In-Memory-Datenverarbeitung entwickelt, was ein starker Gegensatz zum dateisystembasierten Ansatz von Hadoop ist. Der Kern von Spark sind die Resilient Distributed Datasets (RDDs). Die Datenstruktur wird als Abstraktionsebene für alle Operationen auf den Daten verwendet, unabhängig vom eigentlichen Datentyp. Die RDDs organisieren die Daten in unveränderbaren Partitionen, sodass alle Elemente innerhalb eines RDD parallel verarbeitet werden können. Die RDDs sind also ähnlich zu den Key-Value-Paaren, die wir aus MapReduce kennen. Entsprechend ermöglicht Spark auch die Definition von map- und reduce-Funktionen auf den RDDs, sofern diese Key-Value-Paare beinhalten. Man kann jedoch auch beliebige andere Datentypen in RDDs speichern, es müssen also keine Key-Value-Paare sein. Außerdem sind nicht nur map und reduce erlaubt, sondern beliebige UDFs. Bei Bedarf können die Inhalte von RDDs auch persistent gespeichert werden, zum Beispiel in einem Dateisystem oder einer Datenbank, um Ergebnisse zu speichern.
Seit Spark 2.0 gibt es auch Dataframes in Spark, die als weitere Abstraktionsschicht oberhalb der RDDs liegen. Diese Dataframes sind ähnlich zu den Dataframes, die es zum Beispiel in Python mit pandas oder in der Programmiersprache R gibt. Die Dataframes sind direkt in Spark SQL integriert. Da Dataframes ein sehr mächtiger und intuitiver Datentyp sind, ist das Arbeiten mit Apache Spark daher oft für Benutzer einfacher als mit anderen Big-Data-Technologien.
12.6.3. Infrastruktur#
Auch wenn es möglich ist, ein Rechencluster direkt mit Apache Spark zu betreiben, ist dies nicht der Hauptanwendungsfall von Spark. Stattdessen werden die RDDs als Kompatibilitätsschicht zu anderen Technologien genutzt. Spark kann zum Beispiel mit YARN und dem HDFS verwendet werden, sodass die Daten innerhalb eines Hadoop-Clusters mit Spark verarbeitet werden können. Es werden aber auch viele weitere Technologien unterstützt, zum Beispiel Amazons EC2 Clouds und Kubernetes für Berechnungen oder Datenbanken wie Cassandra, HBase und MongoDB. Daher sind Analysen, die auf Apache Spark aufbauen, nicht an eine bestimmte Infrastruktur gebunden und können relativ flexibel in verschiedene Infrastrukturen portiert werden.
12.6.4. Worthäufigkeiten mit Spark#
Auch wenn Spark selbst in Scala entwickelt wird, können Spark-Anwendungen neben Scala auch in Java, Python (PySpark) und R (SparkR) entwickelt werden. Benutzer müssen die Abhängigkeiten zwischen Datenverarbeitungsschritten nicht manuell definieren. Stattdessen geht Spark davon aus, dass die Reihenfolge, in der die Aufgaben definiert werden, auch die Reihenfolge ist, in der die Aufgaben ausgeführt werden. Aufgaben, die nicht dieselben Daten verwenden, werden hierbei parallel ausgeführt. Wenn eine Aufgabe die Ergebnisse eines vorherigen Schritts benötigt, erkennt Spark dies automatisch anhand des Datenflusses und überträgt die Daten mithilfe einer shuffle-Funktion. Daher benötigt man bei Spark weniger Boilerplate-Quelltext zur Definition von Abhängigkeiten als bei Hadoop. Mit PySpark sieht das Worthäufigkeitsbeispiel wie folgt aus:
# sc is the SparkContext, which is similar to the Configuration of Hadoop
text_file = sc.textFile("hdfs://data.txt")
# flatMap can map the input to multiple outputs
# map maps each input to exactly one output
# reduce by key is the same as reduce in Hadoop
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://wc.txt")
Der Quelltext ist deutlich kürzer als bei Hadoop und gleichzeitig einfacher zu lesen. Außerdem sieht man, dass es bei Spark verschiedene Varianten von map und reduce gibt. Bei einer flatMap wird zum Beispiel für jede Ausgabe genau ein Ausgabepaar erzeugt, bei einer map werden, wie oben, beliebig viele Paare erzeugt.
Bemerkung:
Bei
lambda-Funktionen handelt es sich in Python um anonyme Funktionen, die in einer Zeile definiert werden. Der Ausdrucklambda a, b: a+bist zum Beispiel identisch zur Definition zum Aufruf folgender Funktion:def fun(a, b): return a+b
12.7. Jenseits von Hadoop und Spark#
Mit Hadoop und Spark haben wir zwei wichtige Big-Data-Technologien beleuchtet. Aufgrund der Bedeutung von Big Data sind noch sehr viele weitere Technologien entstanden, insbesondere Datenbanken, die für Big Data optimiert wurden, mächtige Stream-Processing-Bibliotheken und Werkzeuge zur Verwaltung von Big-Data-Rechenclustern. Es gibt alleine ein ganzes Ökosystem innerhalb der Apache Foundation rund um Hadoop, Spark und weitere Technologien, die sich alle ergänzen und zu einem gewissen Grad zueinander kompatibel sind. Hinzu kommt ein stetig wachsendes Angebot an vorgefertigten Lösungen von Cloud-Dienstleistern. Diese Technologielandschaft entwickelt sich immer noch weiter und verändert sich ständig, auch wenn einige Kerntechnologien wie Apache Spark, aber auch Apache Kafka für die Streamverarbeitung oder Apache Cassandra als Big-Data-Datenbank kaum noch wegzudenken sind.
Ein positiver Aspekt der Big-Data-Technologielandschaft ist der starke Fokus auf Open Source. Viele State-of-the-Art-Werkzeuge werden als Open Source entwickelt, sodass für die Benutzung der Software in der Regel keine Lizenzkosten entstehen. Dennoch ist die Analyse von Big Data in der Regel relativ teuer, da Administration und Wartung von Infrastrukturen kostenintensiv sind, selbst wenn diese bei einem Cloud-Dienstleister gehostet werden.