
2. Der Prozess von Data-Science-Projekten#
Prozesse sind der Kern jeder Aktivität, auch wenn man sich dessen oft gar nicht bewusst ist. Menschen führen Aktivitäten durch das Anwenden von Techniken durch. Die Prozesse steuern und organisieren diese Aktivitäten und beschreiben die Techniken, die eingesetzt werden. Fig. 2.1 zeigt die Beziehung von Menschen, Techniken und Prozessen.
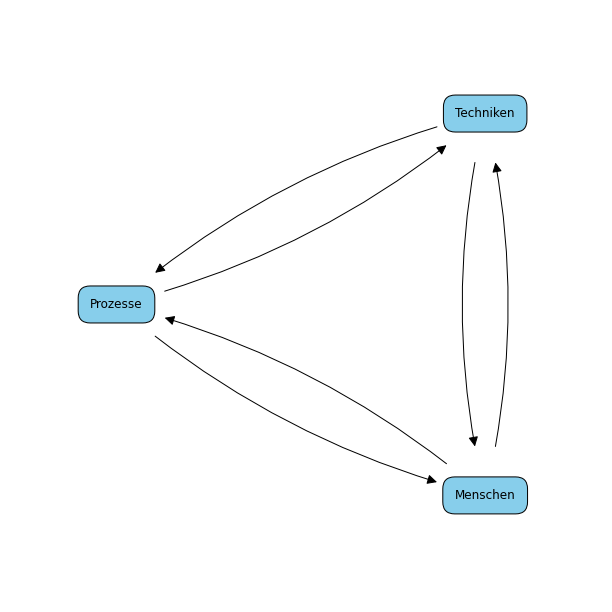
Fig. 2.1 Beziehung von Menschen, Techniken und Prozessen#
Das Ziel eines guten Prozesses ist es, die Menschen zu unterstützen, zum Beispiel indem sichergestellt wird, dass wichtige Aktivitäten nicht vergessen werden, oder durch die Verwendung von geeigneten Werkzeugen zum Lösen von Problemen. Prozesse erreichen dies, indem sie geeignete Best Practices beschreiben. Diese Best Practices sollten auf Basis der erfolgreichen Anwendung in der Vergangenheit bestimmt werden. Hierdurch soll das Wissen und der Erfolg aus vergangenen Projekten konserviert und genutzt werden, um die Fähigkeiten der Menschen zu unterstützen und das Risiko, dass ein Projekt fehlschlägt, zu reduzieren. Dies funktioniert jedoch nur, wenn die Prozesse von Menschen auch unterstützt werden.
Wenn die Menschen den Prozess nicht akzeptieren oder nicht an seinen Nutzen glauben, erreicht man das Gegenteil und erhöht stattdessen das Risiko von Projekten. Daher sollten die Personen die notwendigen Schulungen erhalten, um die Techniken einzusetzen und ihren Nutzen zu kennen. Außerdem muss man sicherstellen, dass die Techniken auch zum Prozess passen.
Man sollte sich auch immer bewusst sein, dass es nicht den einen Prozess gibt, der perfekt zu jedem Projekt passt. Man sollte den Prozess daher immer an die Situation anpassen, man spricht hier auch vom Tailoring. Hierbei sind die zur Verfügung stehenden Techniken und der Projektkontext zu berücksichtigen, zum Beispiel die Größe und Priorität des Projekts, ob es sicherheitskritische Aspekte gibt oder ob die Mitarbeiterinnen Vorwissen aus ähnlichen Projekten mitbringen.
2.1. Der generische Data-Science-Prozess#
Fig. 2.2 zeigt den generischen Prozess für Data-Science-Projekte, der aus sechs Phasen besteht.
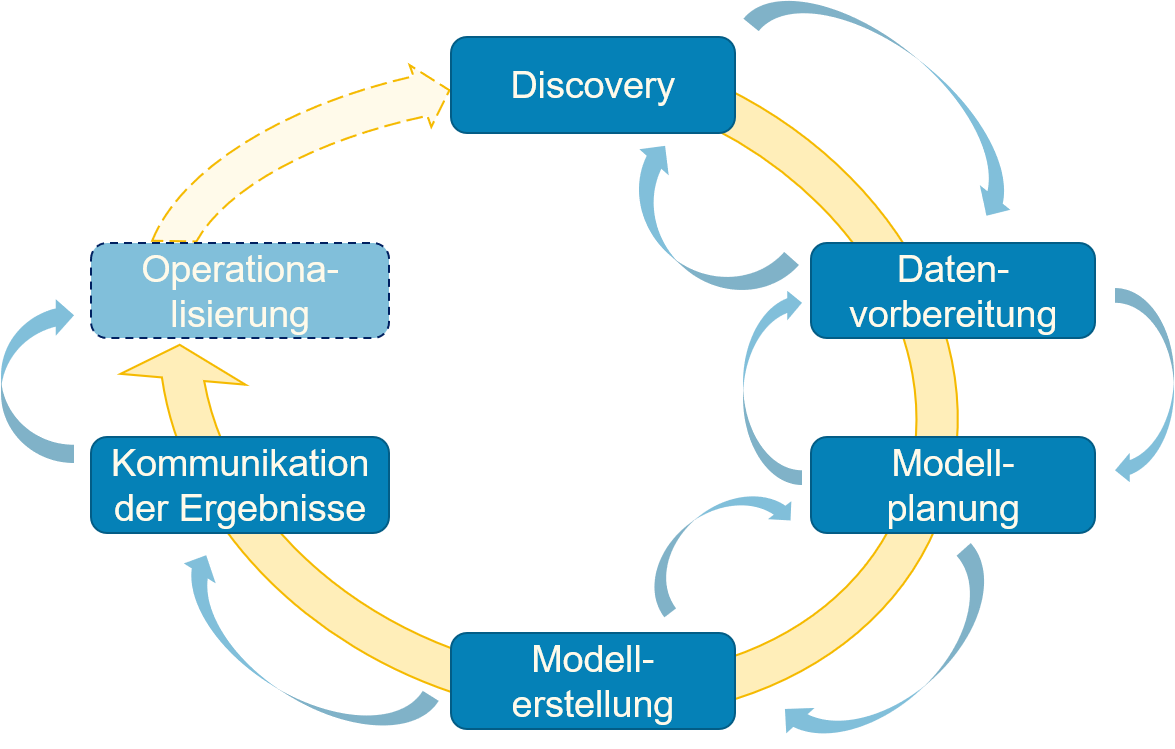
Fig. 2.2 Überblick über den generellen Prozess von Data-Science-Projekten.#
Der Prozess ist iterativ, das heißt, dass mehrere Wiederholungen aller Phasen innerhalb eines Projekts möglich sind. Innerhalb einer Iteration kann man nur zu den vorherigen Phasen zurück, solange man die Ergebnisse der Iteration noch nicht kommuniziert hat. Der Grund hierfür ist offensichtlich: Sobald man die Projektergebnisse übermittelt hat, zum Beispiel an das Management, die Kunden oder andere Forscher in Form einer Publikation, kann man diese nicht ohne Weiteres ändern. Im Folgenden betrachten wir die Projektphasen im Detail.ail.
2.1.1. Discovery#
Jedes Data-Science-Projekt beginnt mit der Discovery Phase. Das Ziel der Discovery ist es, die Projektdomäne, Ziele und Daten zu verstehen. Anhand der gesammelten Informationen wird beurteilt, ob die für das Projekt notwendigen Ressourcen verfügbar sind, und die weiteren Projektschritte werden geplant.
Der Data Scientist muss das notwendige Wissen erlangen, um die Domäne des Projekts zu verstehen, insbesondere den Anwendungsfall, der adressiert werden soll. Häufig wird der Data Scientist hierbei von Domänenexpertinnen unterstützt, die die notwendigen Informationen liefern. Dies kann zum Beispiel bedeuten, dass sie zur Verfügung stehen, um Fragen zu beantworten, oder auch dass Anforderungen in Form von Interviews und Workshops gesammelt werden. Hierdurch lernt der Data Scientist auch bereits die Daten und Informationsquellen kennen. Dieses Wissen ist notwendig, um das Projekt zu verstehen und die Ergebnisse zu interpretieren. Es kann sein, dass der Data Scientist bereits selbst Experte oder Expertin in der Anwendungsdomäne ist, zum Beispiel weil dies nicht das erste derartige Projekt ist. Dennoch ist es häufig sinnvoll, den Anwendungsfall zusammen mit weiteren Domänenexpertinnen zu betrachten, um sicherzustellen, dass keine wesentlichen Aspekte übersehen werden.
Als Teil des Lernprozesses der Domäne sollte auch die Vergangenheit nicht außer acht gelassen werden. Bei Forschungsprojekten ist es in der akademischen Welt üblich, zuerst die verwandten Forschungsarbeiten zu identifizieren und den Stand der Forschung aufzuarbeiten. Ähnlich sollte man auch in der Wirtschaft vorgehen: Gab es vielleicht bereits frühere Projekte mit einem ähnlichen Ziel? Falls ja, warum sind diese gescheitert bzw. warum wird dieses Projekt jetzt neu durchgeführt? Die alten Projektergebnisse – sowohl positive als auch negative – sind ideale Quellen, um Projektrisiken zu identifizieren. Hierbei sollte man sich auch nicht nur auf das eigene Unternehmen beschränken. Im Rahmen der Möglichkeiten des Urheber- und Patentrechts ist eine Analyse der Konkurrenzprodukte oft hilfreich, um mögliche Lösungen zu verstehen.
Sobald der Data Scientist die Domäne verstanden hat, kann er oder sie anfangen, aus den genannten Zielen eine Problembeschreibung zu erarbeiten, die durch die Datenanalyse gelöst werden soll. Diese Problembeschreibung ist nicht identisch zu den wirtschaftlichen Zielen oder Forschungsinteressen: Während die Ziele nicht direkt mit den Daten, sondern eher mit der Anwendung zusammenhängen, formuliert die Problembeschreibung die Ziele als Datenanalyseproblem um. Dies ist dem Data Scientist nur möglich, da er oder sie vorher die Domäne und den Anwendungsfall mithilfe der Domänenexpertinnen kennengelernt hat. Zur Problembeschreibung gehört auch eine Analyse der Stakeholder, zum Beispiel müssen die Stakeholder, deren Daten benötigt werden, identifiziert werden. Weitere wichtige Stakeholder sind diejenigen, die von der Analyse direkt betroffen sind, zum Beispiel weil ihre Arbeit dadurch unterstützt werden soll. Neben Stakeholdern müssen auch die aktuellen Probleme aufgearbeitet werden, sofern dies nicht schon geschehen ist. Hierdurch wird die Motivation vom Projekt geklärt und das Verständnis der Ziele verbessert. Anschließend werden die Projektziele, Erfolgskriterien und Risiken des Projekts klar definiert, um eine verbindliche Grundlage für das weitere Vorgehen zu schaffen.
Durch die oben beschriebenen Aktivitäten bekommt der Data Scientist ein Grundverständnis der Daten, die im Projekt genutzt werden. Grundsätzlich muss man hierbei zwischen Daten, die bereits vorhanden sind (zum Beispiel in einem Data Warehouse), und Daten, die noch gesammelt werden müssen, unterscheiden. In beiden Fällen obliegt es dem Data Scientist, sich zunächst einen Überblick über den Umfang und die Struktur der Daten zu verschaffen sowie ein abstraktes Verständnis der verfügbaren Informationen zu erlangen. Andernfalls wäre die abschließende Analyse der verfügbaren und benötigten Ressourcen nicht möglich.
Während der Discovery befasst man sich auch mit dem wissenschaftlichen Teil von Data Science. Datenanalysen sollten nicht rein explorativ sein. Stattdessen sollten klare Erwartungen in Form von Hypothesen, die getestet werden können, formuliert werden. Andernfalls erhöht man das Risiko, dass die Projektergebnisse sich nicht über die im Projekt verfügbaren Daten hinaus generalisieren lassen. Die Hypothesen steuern auch das Vorgehen in den weiteren Phasen des Projekts. Es sollten zum Beispiel Erwartungen definiert werden, welche Daten nützlich sind, wie man sie verwenden sollte und welches Wissen man aus den Daten gewinnen möchte. Auch wenn der Data Scientist hauptverantwortlich für die Hypothesen ist, sollten diese immer mit Domänenexpertinnen besprochen werden, um ihre Plausibilität zu prüfen.
Der letzte Schritt der Discovery ist die Entscheidung, ob das Projekt machbar ist. Diese Auswertung sollte die identifizierten Risiken und die verfügbaren Ressourcen berücksichtigen. In jedem Fall sollten die folgenden Ressourcen berücksichtigt werden:
Die technologischen Ressourcen, zum Beispiel Datenspeicher, verfügbare Rechenkraft sowie die Verfügbarkeit und die Kosten eventuell benötigter Softwarelizenzen
Die benötigten Daten, das heißt, es stellt sich die Frage, ob bereits ausreichend Daten vorhanden sind oder ob mit vertretbarem Aufwand im Rahmen des Projekts die benötigten Daten zu sammeln sind. Die Betrachtung besteht aus zwei Aspekten: 1) Ist die Anzahl der Datenpunkte ausreichend? 2) Hat man für jeden Datenpunkt die benötigten Informationen? Falls noch Daten gesammelt werden müssen, sollte man dies bei den Projektrisiken immer berücksichtigen.
Die Arbeitszeit, sowohl in Kalenderzeit als auch in Personenmonaten. Die Kalenderzeit ist die Dauer des Projekts. Für Projekte, deren Kalenderzeit weniger als ein Jahr ist, sollte man auch noch berücksichtigen, in welchen Monaten des Jahres das Projekt durchgeführt werden soll, da die üblichen Urlaubszeiten bedeuten können, dass Mitarbeiterinnen nicht wie erwartet zur Verfügung stehen. Wenn Projekte in einem internationalen Umfeld durchgeführt werden, sollte man hierbei auch die lokalen Gepflogenheiten der jeweiligen Projektpartner nicht vergessen. Personenmonate sind ein verbreitetes Mittel, um den Entwicklungsaufwand abzuschätzen, der für ein Projekt investiert wird. Zwei Mitarbeiterinnen, die je einen Monat am Projekt arbeiten, entsprechen zwei Personenmonaten. Man sollte bei der Betrachtung der Arbeitszeit aber nie vergessen, dass zwei Mitarbeiterinnen in der Regel nicht doppelt so effizient sind wie eine Mitarbeiterin. Diese Phänomen ist in der Softwareentwicklung auch als der Mythical Man-Month [1] bekannt.
Die Mitarbeiterinnen (gerne auch Human Resources genannt), das heißt die Personen, die für das Projekt zur Verfügung stehen. Hierbei sollte insbesondere betrachtet werden, ob das Fähigkeitsprofil der Mitarbeiterinnen zu den Anforderungen des Projekts passt.
Die technologische Ressourcen, zum Beispiel Datenspeicher, verfügbare Rechenkraft, sowie die Verfügbarkeit und die Kosten eventuell benötigter Softwarelizenzen.
Die benötigten Daten, das heißt ob bereits ausreichend Daten vorhanden sind oder ob es mit vertretbarem Aufwand im Rahmen des Projektes die benötigten Daten zu sammeln. Die Betrachtung besteht aus zwei Aspekten: 1) Ist die Anzahl der Datenpunkte ausreichend? 2) Hat man für jeden Datenpunkt die benötigten Informationen. Sollten noch Daten gesammelt werden müssen, sollte man dies bei den Projektrisiken immer berücksichtigen.
Die Arbeitszeit, sowohl in Kalenderzeit, als auch in Personenmonaten. Die Kalenderzeit ist die Dauer des Projekts. Für Projekte deren Kalendarzeit weniger als ein Jahr ist, sollte man auch noch berücksichten, in welchen Monaten des Jahres das Projekt durchgeführt werden soll, da die üblichen Urlaubszeiten bedeuten können, das Mitarbeiterinnen nicht wie erwartet zur Verfügung stehen. Wenn Projekte in einem internationalen Umfeld durchgeführt werden, sollte man hierbei auch die lokalen Gepflogenheiten der jeweiligen Projektpartner nicht vergessen. Personenmonate sind ein verbreitetes Mittel um den Entwicklungsaufwand, der für ein Projekt investiert wird, abzuschätzen. Zwei Mitarbeiterinnen, die je einen Monat am Projekt arbeiten, entspricht zwei Personenmonaten. Man sollte bei der Betrachtung der Arbeitszeit aber nie vergessen, dass zwei Mitarbeiterinnen in der Regel nicht doppelt so effizient sind wie eine Mitarbeiterinnen. Diese Phänomen ist in der Softwareentwicklung auch als der Mythical Man-Month [1] bekannt.
Die Mitarbeiterinnen (gerne auch Human Ressources genannt), das heißt die Personen, die für das Projekt zur Verfügung stehen. Hierbei sollte insbesondere betrachtet werden, ob das Fähigkeitsprofil der Mitarbeiterinnen zu den Anforderungen des Projekts passt.
Sofern ausreichend Ressourcen verfügbar und die Risiken kontrollierbar sind, kann das Projekt gestartet werden.
Beispiel:
Ein Kunde ist Besitzer eines Webshops für Kleidung. Der Kunde möchte gerne die Anzahl seiner Verkäufe durch Cross-Selling erhöhen, das heißt, Kunden sollen dazu gebracht werden, weitere Produkte in den Warenkorb zu legen. Unsere Aufgabe ist es, eine Anwendung hierfür zu entwickeln, die auf den vergangenen Verkaufsdaten basiert. Die Discovery könnte in etwa so aussehen:
Wir führen ein Interview mit dem Kunden durch, um herauszufinden, ob der Kunde bereits eine Idee hat, wie mehr Cross-Selling ermöglicht werden könnte. Wir finden heraus, dass der Kunde gezielte Werbung während des Einkaufs schalten möchte, sobald ein Produkt in den Warenkorb gelegt wird.
Diese Information liefert uns eine Kernanforderung des Projekts, andernfalls wäre zum Beispiel auch E-Mail-Marketing denkbar gewesen.
Wir schauen uns Webshops an, die bereits ähnliche Lösungen benutzen.
Wir definieren die Problembeschreibung als das Ziel, geeignete Werbung vorherzusagen, basierend auf dem vergangenen Verhalten des Kunden, dem vergangenen Verhalten aller Kunden sowie dem aktuellen Inhalt des Warenkorbs.
Wir identifizieren zwei wichtige Stakeholder: 1) Den Besitzer des Webshops als Auftraggeber, Ansprechpartner auf Kundenseite und Domänenexperten. 2) Die Kunden des Webshops, die für sich relevante Produkte kaufen wollen und eine gute User Experience (UX) bei der Benutzung der Software wünschen. Unpassende Werbung könnte die Benutzererfahrung verschlechtern, sehr gute Werbung sogar verbessern.
Wir identifizieren keine Probleme mit dem Status quo, die gelöst werden sollen. Es geht also um eine reine Optimierung der Einnahmen.
Aus diesen Erkenntnissen definieren wir zwei konkrete Projektziele:
Erhöhung der Anzahl der verkauften Produkte und dadurch Steigerung des Umsatzes
Gleichbleibende oder verbesserte UX
Die Erfüllung der Projektziele soll durch die Beobachtung des Umsatzes sowie durch eine Umfrage unter den Benutzern bezüglich ihrer Zufriedenheit bestimmt werden. Das Projekt gilt als erfolgreich, wenn der Umsatz sich um mindestens 5% erhöht und die Benutzerzufriedenheit sich nicht verschlechtert. Sie identifizieren eine mögliche Verschlechterung der Benutzerzufriedenheit, die zu einem Abfall des Umsatzes führt, als Hauptrisiko des Projekts.
Als Daten stehen uns hauptsächlich die Transaktionen von vergangenen Einkäufen zur Verfügung. Diese Daten beinhalten, welche Kunden welche Produkte innerhalb einer Bestellung gekauft haben. Die Daten liegen in einer relationalen Datenbank vor. Weitere Daten stehen uns nicht zur Verfügung.
Wir formulieren drei Hypothesen:
Produkte, die in der Vergangenheit häufig zusammen gekauft wurden, werden auch in der Zukunft häufig zusammen gekauft.
Es gibt saisonale Muster in den Verkaufsdaten (zum Beispiel für Winter- und Sommerkleidung), die relevant sind für die Werbung.
Die Kategorien, durch die sich die Produkte beschreiben lassen, sind relevant für die Werbung, insbesondere die Marken und die Art der Kleidung.
Wir sind der Meinung, dass die Ressourcen ausreichen, um eine Pilotstudie durchzuführen, in der die Machbarkeit von nützlichen Vorhersagen für Cross-Selling-Werbung geprüft wird. Eine detaillierte Evaluation der Benutzererfahrung sowie eine Operationalisierung der Ergebnisse für den produktiven Betrieb ist mit den zur Verfügung stehenden Ressourcen nicht realistisch. Im Falle einer erfolgreichen Machbarkeit der Vorhersagen wird dies in einem Folgeprojekt umgesetzt.
2.1.2. Datenvorbereitung#
Mit dem Abschluss der Discovery beginnt die technische Arbeit des Projekts, bei der die Daten für die Analyse vorbereitet werden (engl. preprocessing). Hierbei gibt es zwei wesentliche Ziele:
Die Infrastruktur für die Datenanalyse muss erstellt werden und alle relevanten Daten müssen in diese Infrastruktur geladen werden.
Der Data Scientist sollte ein tiefgehendes und detailliertes Verständnis der Daten erlangen.
Der Aufwand für die Vorbereitung der Infrastruktur hängt stark vom Projekt ab. Er kann nahezu trivial und mit wenigen Zeilen Quelltext erledigt sein oder mehrere Personenjahre an Ressourcen verschlingen. Ist das Datenvolumen relativ klein und die Daten können durch eine einzelne SQL-Abfrage geladen werden, ist diese Aufgabe in kürzester Zeit erledigt. Handelt es sich wiederum um ein Big-Data-Projekt, in dem die Daten erst noch gesammelt werden müssen oder wo der Zugriff auf die Daten schwierig ist (zum Beispiel aus Sicherheits- oder Datenschutzbedenken), kann dies extrem aufwendig sein.
Der grundsätzliche Prozess des Ladens von Daten in die Analyseinfrastruktur wird ETL genannt: Extract, Transform, Load. Zuerst werden die Daten von ihrem aktuellen Speicherort extrahiert. Dies bedeutet, dass der Code zum Laden der Daten aus Dateien und Datenbanken oder zum Sammeln von Daten aus anderen Quellen (zum Beispiel dem Internet durch “Scraping”) geschrieben wird. Sobald die Daten extrahiert sind, werden sie in das benötigte Format konvertiert. Diese Transformation beinhaltet üblicherweise auch die Qualitätskontrolle der Daten: Zum Beispiel kann man hier unvollständige oder nicht plausible Datenpunkte entfernen. Weiterhin müssen die Daten häufig restrukturiert und in andere Formate konvertiert werden. Das kann zum Beispiel bedeuten, dass Informationen aus verschiedenen Quellen integriert werden. Es kann aber auch heißen, dass Informationen neu aufgeteilt werden. Zum Beispiel könnte man den Inhalt von Blogposts in verschiedene Felder aufteilen: Titel, Inhalt und Kommentare. Bei textuellen Daten kann es auch herausfordernd sein, diese in ein einheitliches Textformat zu konvertieren, da es viele verschiedene Codierungen für Textdaten gibt, zum Beispiel ASCII, ISO-8859, UTF-8 und UTF-16, um nur einige gängige zu nennen. Ähnliche Probleme kann es bei Datumsformaten geben. Ob 04/05/21 sich auf den 4. Mai oder den 5. April bezieht, hängt davon ab, ob die amerikanische oder britische Konvention verwendet wird. Ob es sich um das Jahr 2021 oder 1921 handelt, hängt vom Zeitpunkt ab, an dem dieses Datum geschrieben wurde. Sobald alle Daten transformiert sind, können sie in die Analyseumgebung geladen werden.
Häufig kann man ETL auch in ELT abwandeln, indem man die Transformation und das Laden der Daten vertauscht. In diesem Fall werden die Rohdaten direkt in die Analyseumgebung geladen und benötigte Transformationen werden innerhalb der Analyseumgebung durchgeführt. Ob ETL oder ELT die bessere Wahl ist, hängt vom Anwendungsfall ab. Ein guter Grund, warum man ELT statt ETL nutzen sollte, besteht darin, dass die Transformationen so komplex sind, dass man sie ohne die Rechenkraft der Analyseumgebung nicht durchführen kann. Ein weiterer Vorteil von ELT ist, dass man verschiedene Transformationen ausprobieren und flexibel miteinander vergleichen kann. Zuletzt gibt es auch Anwendungen, die vom Zugriff auf die Rohdaten profitieren können, da diese zum Beispiel dann auch von Algorithmen als Merkmal verwendet werden können. Auf der anderen Seite ist ETL zu favorisieren, wenn die Transformationen sehr zeitaufwendig sind und nicht mehrfach bei jedem Laden der Daten durchgeführt werden sollen oder wenn man die Transformationen direkt bei einem Datenbankzugriff durchführen kann.
Ein weiterer wesentlicher Aspekt der Datenvorbereitung ist das detaillierte Verständnis der Daten. Dies bedeutet das Studium der Dokumentation der Daten. Sofern diese nicht vorhanden oder nicht ausreichend ist, müssen die Daten mithilfe von Domänenwissen interpretiert werden. Im Idealfall kennt der Data Scientist zum Abschluss dieser Phase alle Details der Daten, zum Beispiel die Bedeutung jeder Spalte in einer relationalen Datenbank oder welche Arten von Dokumenten es gibt und wie diese strukturiert sind. Diese Arbeit kann man auch als Lernen der Metadaten bezeichnen, also der Daten über die Daten. Zusätzlich zu den Metadaten sollten auch die Daten selbst erkundet werden - eine Aktivität, die häufig eng mit den Transformationen von ETL zusammenhängt. Hierzu betrachtet man zum Beispiel Statistiken und Visualisierungen (siehe Kapitel 4). Hierdurch kann man beispielsweise Erkenntnisse über die Wahrscheinlichkeitsverteilungen der Daten gewinnen, ungültige Daten identifizieren oder Skaleneffekte entdecken und entfernen, um die Daten besser zu vereinheitlichen.
Diese detaillierte Betrachtung der Daten erlaubt es dem Data Scientist auch, zu erkennen, welche Daten wirklich wertvoll für das Projekt sind und welche Daten eventuell doch nicht benötigt werden. Hierbei muss man ein gesundes Mittelmaß finden: Auf der einen Seite geht man ein Risiko ein, wenn man Daten frühzeitig entfernt, da man etwas übersehen haben könnte und die Daten eventuell doch nützlich wären. Auf der anderen Seite reduziert man die Komplexität des Projekts, wenn weniger Daten vorhanden sind. Insbesondere wenn große Datenmengen entfernt werden können, kann sich der Analyseaufwand stark reduzieren.
Am Ende der Datenvorbereitung sind alle Daten für die Analyse verfügbar und alle benötigten Transformationen sind definiert und durchgeführt.
Beispiel:
Die Verkaufsdaten sind in einer relationalen Datenbank gespeichert, die 352.152 Transaktionen beinhaltet. Im Mittel wurden 2,3 Gegenstände in einer Transaktion gekauft. Für jede Transaktion sind ein Zeitstempel im ISO-8601-Format und ein pseudonymisierter Identifier des Benutzers, der die Gegenstände gekauft hat, verfügbar. In einer zweiten Tabelle werden die Informationen über die Gegenstände selbst gespeichert, unter anderem: der Preis und die Kategorien, denen ein Gegenstand zugeordnet ist (Herrenbekleidung, Damenbekleidung, Hose, Pullover, Socken, Herstellermarke). Es gibt noch weitere Daten, wie zum Beispiel die Bezahlart, diese werden jedoch als für dieses Projekt nicht relevant eingestuft und nicht für die Analyse verwendet. Das Datenvolumen beträgt ca. ein Gigabyte. Daher entscheiden wir uns für einen ELT-Prozess, da das Laden der Daten aus der Datenbank nur etwa eine Minute dauert und man die Daten flexibel in der Analyseumgebung erkunden kann und währenddessen die benötigten Transformationen definiert. Beim Erkunden der Daten entdecken wir 2.132 Transaktionen ohne Gegenstände. Diese entfernen wir, da es sich um ungültige Datenpunkte handelt. Außerdem stellen wir fest, dass die Kleidung einiger Marken nur selten gekauft werden. Daher fassen wir diese Marken in einer neuen Kategorie “Sonstige Marken” zusammen. Wir bestimmen außerdem vier Repräsentationen der Transaktionen, die für die Cross-Selling-Analyse nützlich sein könnten:
Identisch zur Datenbank, das heißt direkt durch die verkauften Gegenstände.
Die Gegenstände werden durch die Art der Kleidung ersetzt.
Die Gegenstände werden durch die Marke ersetzt.
Die Gegenstände werden durch die Kombination von der Art der Kleidung und der Marke ersetzt. Die verschiedenen Repräsentationen ermöglichen es Ihnen, das Cross-Selling auf bestimmte Kleidungstypen oder Marken zu fokussieren.
2.1.3. Modellplanung#
Das Ziel der Modellplanung ist das Design des Analysemodells. Hierzu muss man aus den verschiedenen Möglichkeiten, wie die Datenanalyse gestaltet werden kann, ein geeignetes Modell auswählen, das sowohl zu den Daten als auch zum Analyseziel passt. Es gibt verschiedene Aspekte, die bei der Modellauswahl berücksichtigt werden müssen. Das Projektziel gibt üblicherweise die grundsätzliche Art des Modells vor:
Assoziationsregeln können benutzt werden, um Regeln zu finden, die relevante Beziehungen innerhalb von Transaktionen beschreiben (Kapitel 5).
Clusteranalyse ist dazu geeignet, Gruppierungen innerhalb von Daten zu finden (Kapitel 6).
Klassifikation wird benutzt, um vorherzusagen, zu welcher Kategorie Daten gehören (Kapitel 7).
Regressionsmodelle beschreiben den Zusammenhang zwischen Merkmalen der Daten und können benutzt werden, um kontinuierliche Werte vorherzusagen (Kapitel 8).
Zeitreihenanalyse berücksichtigt zeitliche Abhängigkeiten zwischen Datenpunkten, um zukünftige Entwicklungen abzuschätzen (Kapitel 9).
Bei der Modellplanung muss man aus den vielen Möglichkeiten, wie man zum Beispiel ein Klassifikationsmodell erstellen kann, eine für das Projekt passende auswählen. Es gibt viele Aspekte, die diese Auswahl beeinflussen. Hier sind einige wichtige Fragen, deren Beantwortung bei der Modellauswahl hilft:
Ist es wichtig, dass man die Modelldetails als Mensch nachvollziehen kann, oder reicht es, wenn das Modell definierten Metriken gemäß gut ist? Ein Whitebox-Modell kann vom Data Scientist und eventuell sogar von Domänenexperten benutzt werden, um die Logik, die das Modell verwendet, im Detail nachzuvollziehen. Dies kann zum Beispiel wichtig sein, damit die Nutzer des Modells in der Lage sind, Verantwortung für die Entscheidungen, die mithilfe der Modelle getroffen werden, zu übernehmen. Wenn dies für den Anwendungsfall als weniger wichtig betrachtet wird, kann man auch Blackbox-Modelle verwenden. Hier versteht man dann zwar in der Regel nicht, wie die Entscheidungen zustande gekommen sind, dafür sind solche Modelle häufig präziser. Der Grund für die höhere Präzision liegt darin, dass die interne Komplexität nicht von der Interpretierbarkeit beschränkt ist. Ein Beispiel für ein Whitebox-Modell sind Entscheidungsbäume, in denen anhand einfacher Regeln (größer, kleiner, gleich) Merkmale in einer festgelegten Reihenfolge bewertet werden, um zu einer Entscheidung zu gelangen. Ein Beispiel für Blackbox-Modelle sind tiefe neuronale Netze (engl. Deep Neural Networks, DNN), in denen es Millionen von Parametern gibt, die eine für Menschen nicht nachvollziehbare mathematische Funktion beschreiben. Eventuell ist die Nachvollziehbarkeit der Entscheidungen sogar ein zwingendes Kriterium, wie es derzeit (für einige Anwendungen) im Rahmen einer neuen EU-Richtlinie für künstliche Intelligenz angedacht wird.
Wie hoch ist das Datenvolumen? Obwohl in der Regel alle Modelle besser werden, wenn mehr Daten zur Verfügung stehen, gibt es starke Unterschiede zwischen den Modellen. Auf der einen Seite steht die Modellperformance, die sich mit der Datengröße für unterschiedliche Modelle mit anderen Trends entwickelt (Fig. 2.3). Auf der anderen Seite geht es um die Laufzeit für das Training und die Vorhersagen: Wenn die Berechnungen zu komplex sind, kann es schwierig sein, ein Modell mit einem großen Datenvolumen zu trainieren.
Welche Modelle wurden in der Vergangenheit in diesem Kontext erfolgreich verwendet? Hier sollte man auf das gesammelte Wissen aus der Discovery zurückgreifen.
Mit welchen Modellen hat das Projektteam die meiste Erfahrung? Gerade wenn es mehrere geeignete Kandidaten gibt, ist es sinnvoll, ein Modell zu wählen, das von den Mitarbeiterinnen bereits gut verstanden wird.
Damit Data Scientists ein geeignetes Modell auswählen können, ist es wichtig, dass sie nicht nur Detailwissen über wenige Modelle haben, sondern eine Vielzahl von Modellen kennen, um für jeden Kontext geeignete Modelle identifizieren zu können.
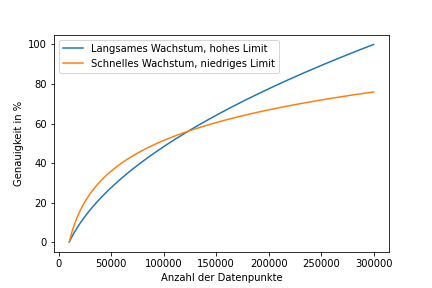
Fig. 2.3 Vergleich der Güte zweier fiktiver Modelle, bezogen auf die Datengröße.#
In Fig. 2.3 ist zu erkennen, dass das orange Modell besser ist, wenn nur wenige Daten zur Verfügung stehen. Das blaue Modell ist besser, wenn viele Daten verfügbar sind. In diesem fiktiven Beispiel könnte das orange Modell für Random Forests und das blaue Modell für tiefe neuronale Netze stehen. Diese Modelle werden in Kapitel 7 eingeführt.
Auch wenn die Auswahl des Modells ein entscheidender Faktor für den Projekterfolg ist, macht sie in der Regel nur einen relativ kleinen Teil der Modellplanung aus. Weitere wichtige Aktivitäten sind:
Die Auswahl von Merkmalen (engl. feature), die die Grundlage für die Modelle sind. Hierbei müssen auch die genauen Berechnungsvorschriften für die Merkmale definiert werden und der Umgang mit Daten, die nicht plausibel sind.
Die Auswertungskriterien für die Modelle müssen durch Gütemaße definiert werden, mit denen die Modellqualität bewertet werden kann. Die Gütemaße können zum Beispiel in Bezug auf die allgemeine Genauigkeit oder bestimmte Fehlerklassen definiert werden.
Statistische Methoden und Visualisierungen zur Interpretation der Ergebnisse müssen definiert werden.
Die Daten müssen eventuell in verschiedene Teilmengen unterteilt werden, zum Beispiel in Trainingsdaten zum Trainieren von Modellen, Validierungsdaten zur Auswahl des besten Modells und Testdaten zur Bewertung der Güte des besten Modells (siehe Kapitel 3).
Im Fall von Big Data muss eine Arbeitsumgebung geschaffen werden, in der man mit den Daten oder einer kleinen Teilmenge der Daten experimentieren kann.
Beispiel:
Wir entscheiden uns für den Apriori-Algorithmus zum Bestimmen von Assoziationsregeln, um Produkte, die häufig gemeinsam gekauft wurden, zu identifizieren. Für die Varianten der Daten, in denen wir die Produkte durch Kategorien ersetzt haben, möchten wir ein Random-Forest-Regressionsmodell nutzen, um vorherzusagen, mit welcher Wahrscheinlichkeit bestimmte Produkte gekauft werden, basierend auf dem Inhalt des Warenkorbs. Je nach Qualität der Ergebnisse dieser Modelle planen wir außerdem noch, die Modelle gegebenenfalls in einer zweiten Iteration zu verändern, um Verbesserungen zu erreichen. Als ein Risiko, das zu einer solchen zweiten Iteration führen kann, sehen wir, dass eventuell zu viele günstige Produkte vorhergesagt werden, sodass selbst richtige Vorhersagen nur geringe Auswirkungen auf den Umsatz haben würden. Die Güte der Modellquali-tät bewerten wir auf Basis der Häufigkeit wie zufällig aus dem Warenkorb entfernte Gegenstände richtig vorhergesagt werden. Um die Analyse der Modellqualität zu unterstützen, planen wir, eine Visualisierung zu erstellen, die uns hilft zu verstehen, welche Produkte häufig gemeinsam gekauft werden. Außerdem entschließen wir uns, unsere Daten anhand der Zeitstempel in drei Teildatensätze zu unterteilen: Die ältesten 50% der Daten sollen zum Trainieren der Modelle benutzt werden, die nächsten 25% als Validierungsdaten und die neuesten 25% als Testdaten.
2.1.4. Modellerstellung#
Zur Modellerstellung müssen wir den notwendigen Code schreiben, um die geplanten Modelle zu trainieren. Häufig gibt es mehrere Iterationen zwischen der Modellplanung und der Modellerstellung. Innerhalb dieser Iterationen wird das Modell stückweise basierend auf den Erkenntnissen von Zwischenauswertungen verbessert. So können zum Beispiel Probleme, die man spät in den Daten entdeckt, noch behoben oder Potenziale für die Verbesserung genutzt werden. Wichtig ist jedoch, dass für diese iterativen Verbesserungen nur die Trainings- und Validierungsdaten verwendet werden. Die Testdaten darf man nur zur abschließenden Bewertung der Modellqualität benutzen. Wenn die Testdaten mehrfach verwendet werden, degenerieren sie zu Validierungsdaten (siehe Kapitel 3).
Man könnte die Modellplanung und die Modellerstellung auch als eine Phase betrachten. Der Grund, weshalb wir diese hier als getrennte Phasen beschreiben, besteht darin, dass die Modellerstellung sehr teuer und zeitintensiv sein kann, zum Beispiel wenn riesige neuronale Netze in einem gemieteten Cluster in der Cloud trainiert werden. Da dies nicht oft wiederholt werden kann, hilft es, das Training als separaten Teil des Prozesses hervorzuheben.
Beispiel:
Wir entschließen uns, das Modell mit der Programmiersprache Python basierend auf den Bibliotheken pandas, scikit-learn und mlextend zu erstellen. Wir können das Modell auf einer normalen Workstation trainieren und evaluieren.
2.1.5. Kommunikation der Ergebnisse#
Irgendwann kommt der Punkt, an dem der Zyklus von iterativen Modellplanungs- und Modellerstellungsschritten beendet wird und die finalen Projektergebnisse kommuniziert werden. Üblicherweise ist dies entweder der Fall, wenn die Zeit oder die geplanten Ressourcen verbraucht sind, die gewünschte Modellqualität erreicht ist, keine Verbesserungen mehr möglich sind oder es absehbar ist, dass kein adäquates Modell gefunden wird. Die Projektergebnisse müssen dann den relevanten Stakeholdern mitgeteilt werden. Welche dies sind, hängt vom Projekt ab. In der Industrie können das zum Beispiel die Kunden oder das höhere Management sein. In der Hochschule könnte das der Betreuer einer Abschlussarbeit sein oder andere forschende Personen. Die Form, in der die Ergebnisse kommuniziert werden, hängt ebenfalls vom Kontext ab. Häufig gibt es eine Abschlusspräsentation, eventuell auch Projektberichte oder wissenschaftliche Fachartikel.
Egal in welcher Form die Ergebnisse kommuniziert werden, der wichtigste Aspekt ist, dass klar wird, ob die Projektziele erreicht wurden oder nicht und, als direkte Folgerung, ob das Projekt erfolgreich war. Zusätzlich sollte man noch die wichtigsten Erkenntnisse des Projekts herausstreichen, zum Beispiel ob das Modell Gewinne erhöht oder Kosten reduziert, wie der erwartete Return on Investment (ROI) ist oder welche Auswirkungen auf das operative Geschäft oder weitere Projekte erwartet werden. Domänenexpertinnen sind häufig auch an Details interessiert, zum Beispiel welche Merkmale wichtig sind und wie diese mit den Ergebnissen zusammenhängen. Gerade wenn etwas Unerwartetes passiert, kann dies zu spannenden Erkenntnissen führen. Bei Forschungsprojekten kommt hinzu, dass man auch klar kommunizieren muss, inwiefern die Erkenntnisse den Stand der Forschung voranbringen.
Beispiel:
Die Assoziationsregeln für Kategorien von Produkten in Kombination mit der Vorhersage von geeigneten Gegenständen durch das Regressionsmodell liefern die besten Ergebnisse. Wir schätzen, dass sich die Verkäufe um 10% erhöhen lassen und dass der Umsatz hierdurch um 6% steigen wird. Wir finden außerdem heraus, dass unsere Modelle nur dann zuverlässig funktionieren, wenn wir zwischen Damen- und Herrenbekleidung unterscheiden. Andernfalls sagt das Regressionsmodell zu häufig Damenbekleidung voraus.
2.1.6. Operationalisierung#
Wenn die Ergebnisse des Modells gut genug sind, wird unter Umständen die Entscheidung getroffen, das Modell im operationellen Betrieb einzusetzen. Hiermit ist in der Regel ein signifikanter Aufwand verbunden: Oft muss das Modell in der operationellen Umgebung neu implementiert werden. Hierbei müssen sowohl die Sicherheitsaspekte der Umgebung als auch die Lauftzeitanforderungen respektiert werden. Wenn das Modell zum Beispiel direkt innerhalb einer Datenbank ausgeführt werden soll, muss man es in der Regel von Grund auf neu programmieren. Wegen dieses oft hohen Aufwands ist die Operationalisierung häufig ein separates Projekt.
Wenn man sich dafür entscheidet, ein Modell in den operationellen Betrieb zu übernehmen, sollte dies pilotiert, also zuerst in einem kleinen Kontext ausprobiert werden. Diese Pilotstudie ist ein Sicherheitsnetz und soll gewährleisten, dass die Erwartungen bezüglich der Modelleigenschaften, die man auf den Testdaten überprüft hat, auch im operationellen Betrieb gültig sind. Es kann zum Beispiel Unterschiede geben, weil sich die Benutzer nicht so verhalten, wie wir dies erwarten, da sich das Nutzerverhalten im Laufe der Zeit verändert hat.
Die Alterung der Daten ist ein Problem für die Operationalisierung, das man nicht unterschätzen sollte: Nicht nur die Daten altern, sondern auch die Modelle. Als Folge verschlechtert sich häufig die Güte der Modelle mit der Zeit. Damit dies kein Problem wird, sollte als Teil der Operationalisierung definiert werden, wann und wie die Modellqualität regelmäßig überprüft wird und unter welchen Umständen das Modell durch ein auf neuen Daten trainiertes Modell ersetzt wird.
Beispiel:
Unser Kunde ist zufrieden mit den Projektergebnissen und möchte das Modell in seinem Webshop durch eine Pilotstudie testen. Die Pilotstudie zeigt die Vorhersagen bei zufällig ausgewählten Kunden und protokolliert, ob weitere Produkte basierend auf den Vorhersagen gekauft wurden. Die Pilotstudie läuft einen Monat. Unabhängig davon, ob Nutzer die Vorhersagen sehen oder nicht, werden alle Nutzer eingeladen, an einer Umfrage zur Zufriedenheit mit dem Webshop teilzunehmen. Diese Umfrage soll zeigen, wie sich die gezielt platzierte Werbung auf die Kundenzufriedenheit auswirkt. Nach Abschluss der Pilotstudie wird die Entscheidung getroffen, ob das Modell in Zukunft immer eingesetzt wird, ob basierend auf der Umfrage Verbesserungen in Bezug auf die Kundenzufriedenheit notwendig sind oder ob sich der Einsatz nicht lohnt, da die platzierte Werbung ignoriert wird.
2.2. Rollen in Data-Science-Projekten#
In jedem Prozess gibt es Rollen, die ausgefüllt werden müssen. Eine Rolle ist eine Funktion oder Tätigkeit, die einen bestimmten Teil einer Operation oder eines Prozesses durchführt. Mit anderen Worten: Rollen beschreiben die Verantwort-lichkeiten und Aufgaben der Personen, die an einem Prozess beteiligt sind. In der Praxis sind Rollen oft mit Jobtiteln verbunden, zum Beispiel “Softwareentwickle-rin”, “Projektmanagerin” oder “Data Scientist”. Im Allgemeinen gibt es jedoch keine Eins-zu-eins-Beziehung von Rollen und Personen. Eine Person kann mehrere Rollen ausfüllen und mehrere Personen können die gleiche Rolle haben. Es kann zum Beispiel mehrere “Data Scientists” in einem Projekt geben und diese “Data Scientists” können noch weitere Rollen haben. Einer könnte zum Beispiel noch zusätzlich der “Projektmanager” sein, eine andere die “Datenbankadminist-ratorin”.
Wir betrachten sieben Rollen in Data-Science-Projekten. Bitte beachten Sie, dass es in der Praxis, insbesondere in großen Projekten oder im Rahmen der Operationalisierung, häufig noch weitere Rollen gibt, zum Beispiel Softwareentwicklerinnen, Softwarearchitektinnen, Cloud-Architektinnen, Community Managerinnen und Testerinnen. Außerdem betrachten wir das Rollenmodell aus der Perspektive der Industrie. Es gibt jedoch für jede Rolle auch ein Gegenstück in der akademischen Welt, das wir auch anführen.
2.2.1. Anwenderin#
Die Anwenderinnen sind der Teil der Zielgruppe, die später die Projektergebnisse direkt benutzen sollen. Sie sind daher wichtige Stakeholder und häufig auch Domänenexpertinnen, die man für ein besseres Verständnis konsultieren kann. Die Anwenderinnen können helfen, die Daten zu verstehen und die Güte der Ergebnisse einzuordnen, um die Rolle eines Projekts in einem Geschäftsprozess zu verstehen. Auch wenn man die Anwenderinnen immer konsultieren sollte, ist dies spätestens dann zwingend notwendig, wenn die Projektergebnisse operationalisiert werden sollen. In akademischen Projekten sind alle, die die Forschungsergebnisse direkt oder indirekt in ihrer täglichen Arbeit nutzen, die Anwender. Wenn Forschung sich bereits im Stadium des Industrietransfers befindet, sind die Anwenderinnen die gleichen wie bei industriellen Projekten. In der akademischen Welt sind die Anwenderinnen in der Regel andere Forscherinnen.
Auch wenn die Anwenderinnen eine wichtige Rolle in Projekten innehaben, was sich auch insbesondere in modernen agilen Prozessmodellen wie Scrum widerspiegelt , werden sie häufig nicht im Tagesgeschäft von Projekten, sondern eher zu festen Zeitpunkten konsultiert.
2.2.2. Projektsponsorin#
Ohne die Sponsorin gäbe es kein Projekt. Die Projektsponsorinnen entscheiden, welche Projekte gestartet werden, und stellen die benötigten Ressourcen bereit. Entsprechend könnten die Projektsponsorinnen die Mitglieder des Managements einer Firma sein oder aber auch Kundinnen, die einen Auftrag erteilen. Die Projektsponsorinnen sind auch für die Beurteilung, ob ein Projekt erfolgreich ist, wichtig. Sie entscheiden, ob sie mit den Ergebnissen zufrieden sind und ob weitere Ressourcen für Folgeprojekte bereitgestellt werden, zum Beispiel um ein Ergebnis zu operationalisieren. In der akademischen Welt sind die Projektsponsorinnen in der Regel die Principal Investigator (PIs), also Professorinnen und Postdoktorandinnen.
Ähnlich wie die Anwenderinnen sind die Projektsponsorinnen in der Regel nicht im Tagesgeschäft involviert. Stattdessen sind sie nur an Meilensteinen beteiligt, wenn wesentliche Projektergebnisse vorgestellt werden und wichtige Entscheidungen getroffen werden müssen.
2.2.3. Projektmanagerin#
Die Projektmanagerin organisiert die Projektarbeit und das Tagesgeschäft. Die Aufgaben umfassen unter anderem die Ressourcenplanung (finanziell, Betreuung der Mitarbeiterinnen, Rechenzeit) sowie die Überwachung des Projektfortschritts. Die Projektmanagerin ist dafür verantwortlich, dass Meilensteine und Projektziele zu den geplanten Zeitpunkten erreicht und die Qualitätsziele dabei erfüllt werden. Damit dies gewährleistet ist, bewertet die Projektmanagerin regelmäßig die Risiken und leitet sofern notwendig Maßnahmen zur Minimierung des Risikos ein. Im Extremfall kann das bedeuten, dass die Projektmanagerin auch entscheiden muss, dass ein Projekt gescheitert ist und nicht fortgeführt wird. Alternativ könnten aber auch zusätzliche Ressourcen beantragt oder die Ziele angepasst werden. Im akademischen Umfeld ist die Projektmanagerin in der Regel auch die Projektsponsorin oder eine wissenschaftliche Mitarbeiterin der Projektsponsorin.
2.2.4. Dateningenieurinnen#
Eine Dateningenieurin beschäftigt sich mit dem ELT/ETL der Daten und ist verantwortlich dafür, die Daten in einer skalierbaren Analyseumgebung zur Verfügung zu stellen. Die Dateningenieurinnen brauchen daher ein gutes Verständnis der Technologien zum Sammeln, Speichern und Verarbeiten von Daten. Insbesondere bei Big-Data-Projekten oder wenn größere Mengen an Daten noch gesammelt werden müssen, kann dies sehr herausfordernd sein. In akademischen Projekten gibt es in der Regel keine Trennung zwischen der Dateningenieurin und dem Data Scientist. In einigen Disziplinen ist das Bereitstellen der Daten jedoch so aufwendig, dass es auch hier Spezialistinnen gibt, zum Beispiel in der Genetik und der Hochenergiephysik. Das Human Genome Project [2] und das CERN [3] sind daher nicht nur für die Biologie und Physik hochrelevant, sondern auch Treiber von Technologien zum Umgang mit großen Datenmengen.
2.2.5. Datenbankadministratorin#
Die Datenbankadministratorin unterstützt die Dateningenieurinnen und Data Scientists durch die Bereitstellung und Administration von Datenbanken als Teil der Analyseumgebung für das Projekt. Die Aufgaben umfassen die Installation und Konfiguration von (verteilten) Datenbanken und Rechenclustern, inklusive der benötigten Werkzeuge für die Datenanalyse. Ob diese Rolle mit der Dateningenieurin oder dem Data Scientist zusammenfällt, hängt von der Organisation ab: Wenn es zum Beispiel ein extra Rechenzentrum gibt oder eine Organisationseinheit für die Nutzung und Bereitstellung von Cloud-Ressourcen, wird die Rolle in der Regel separat gehandhabt. Andernfalls fallen diese Aufgaben häufig direkt mit anderen Tätigkeiten im Projekt zusammen.
2.2.6. Data Scientist#
Der Data Scientist ist Experte für die Datenanalyse und Modellierung und hierfür verantwortlich. Daher muss man als Data Scientist ein detailliertes Verständnis von Modellierungs- und Analysetechniken mitbringen, damit für ein Projekt geeignete Methoden ausgewählt werden können. Als Data Scientist trägt man wesentliche Verantwortung für den Projekterfolg und das Erreichen der Projektziele. Wenn klar wird, dass dies nicht möglich ist oder Risiken identifiziert werden, muss man als Data Scientist eng mit dem Projektmanagement zusammenarbeiten, um geeignete Schritte einzuleiten. Die Rolle des Data Scientist ist eng verwandt mit der Rolle von Business Intelligence Analysts, die es bereits in der Industrie gibt. Bei Business Intelligence handelt es sich gewissermaßen um den Vorreiter von Data Science in der Industrie, wobei hier der Fokus eher auf der Analyse des Status quo liegt, während Data-Science-Projekte häufig auch in die Zukunft blicken, um Vorhersagen und automatisierte Entscheidungen zu ermöglichen.
2.3. Deliverables#
Als Deliverables bezeichnet man greifbare und virtuelle Projektergebnisse. Welche Deliverables erstellt werden, wird häufig als Teil des Projektplans und in Verträgen definiert und ist eng verbunden mit den Meilensteinen von Projekten. Die Deliverables müssen die Erwartung der Stakeholder erfüllen und sind ein wesentliches Kriterium für den Projekterfolg. Bei Data-Science-Projekten gibt es üblicherweise verschiedene Deliverables, von denen wir die wichtigsten hier nennen wollen.
2.3.1. Sponsorenpräsentation#
Die Sponsorenpräsentation adressiert das große Ganze und hat in der Regel eine nicht technische Zielgruppe, wie Anwenderinnen, Projektsponsorinnen und das Projektmanagement. Der Fokus der Sponsorenpräsentation sollte daher auf klaren Botschaften bezüglich des Anwendungsfalls liegen. Man sollte die Güte eines Modells zum Beispiel nicht durch eines der im maschinellen Lernen verwendeten Gütemaße ausdrücken, sondern eher in für den Geschäftsprozess relevanten Kriterien. Man sollte zum Beispiel nicht von “wahr-positiven”, sondern von dem Prozentsatz von korrekt identifizierten Kundinnen sprechen. Die Präsentation sollte darauf ausgelegt sein, die Entscheidungsfindung zu stützen. Was genau das bedeutet, hängt vom Kontext und den Adressatinnen ab. Für Anwenderinnen könnte man die Präsentation zum Beispiel auf die zu erwartenden Änderungen im Geschäftsprozess zuschneiden.
Einfache Visualisierungen wie Balkendiagramme, Liniendiagramme und eventuell einfache Histogramme können hierbei unterstützend eingesetzt werden. Bei Histogrammen sollten die Bins so gewählt werden, dass sie intuitiv Sinn ergeben. Detaillierte Visualisierungen über Modelldetails sollten vermieden werden.
2.3.2. Analystenpräsentation#
Die Analystenpräsentation ist an eine technisch versierte Zielgruppe gerichtet, zum Beispiel andere Data Scientists. Diese Präsentation sollte ebenfalls das große Ganze und die Kernbotschaften abdecken. Es sollte jedoch auch betrachtet werden, wie die Datenanalyse durchgeführt wurde, zum Beispiel welche Algorithmen verwendet wurden. Je nach Zielgruppe und der zur Verfügung stehenden Zeit kann man beliebig tief in die Modelldetails abtauchen oder muss diese eher oberflächlich behandeln. Im Allgemeinen sollte man in dieser Präsentation nichts “Offensichtliches” wiederholen: Wenn Standardalgorithmen verwendet wurden, sollte man diese zum Beispiel nicht ausführlich beschreiben. Stattdessen sollte der Fokus eher auf Aspekten wie unerwarteten Problemen, die aufgetaucht sind, kreativen Lösungsansätzen und neu entwickelten Verfahren liegen.
Insgesamt kann die Analystenpräsentation also deutlich komplexer sein als die Sponsorenpräsentation. Dennoch sollte man immer im Blick behalten, dass die Zielgruppe in der zur Verfügung stehenden Zeit die präsentierten Inhalte auch “verdauen” kann. Man kann also durchaus komplexere Visualisierungen verwenden, wenn diese jedoch mit Details überladen werden, ist dies kontraproduktiv.
2.3.3. Quelltext#
Der zur Datenanalyse entwickelte Quelltext ist in der Regel auch ein Deliverable. Dieser Quelltext ist oft nur ein Prototyp und kein auf Wiederverwendbarkeit ausgelegtes Werkzeug oder eine Programmbibliothek. Meistens liegt nur ein Haufen von Quelltextdateien und ausführbaren Skripten vor. Im schlimmsten Fall beinhalten diese sogar noch maschinenspezifische Informationen, wie lokale Pfade zu den Daten. Auch wenn Clean Code ein sekundärer Aspekt ist, sollte dennoch auch hier bereits auf die Wiederverwendbarkeit geachtet werden. Der Quelltext ist nämlich gleichzeitig auch eine exakte Spezifikation der erstellten Modelle. Daher ist der Quelltext, egal wie “hacky” er ist, eine wichtige Ressource, auch wenn er möglicherweise neu geschrieben, aufgeräumt oder adaptiert werden muss.
2.3.4. Technische Spezifikation#
Zur Ausführung des Quelltextes muss man die technische Spezifikation kennen. Hier werden die Befehle und die Umgebung zur Ausführung beschrieben, zum Beispiel welche Betriebssysteme unterstützt werden, welche Softwarepakete benötigt werden, welche Abhängigkeiten verfügbar sein müssen und wie der Quelltext übersetzt und ausgeführt werden kann. Häufig wird dies vernachlässigt, sodass die technische Spezifikation fehlt, nicht aktuell oder unvollständig ist. In der Konsequenz ist der Quelltext nicht oder nur mit hohem Aufwand nutzbar. Gute Data Scientists sorgen dafür, dass dies nicht der Fall ist, zum Beispiel durch Replication Kits mit allen Informationen zur Replikation der Ergebnisse in der Forschung und saubere Paketierung des Quelltextes in der Industrie.
2.3.5. Daten#
Wenn im Rahmen eines Projekts Daten gesammelt werden, sind diese Daten selbst eventuell auch ein Deliverable. Durch das Teilen oder Archivieren der Daten kann man die Durchführung zukünftiger Projekte ermöglichen oder unterstützen. Insbesondere in der Forschung ist das Teilen von Daten üblich und wichtig, um es anderen forschenden Personen zu ermöglichen, Ergebnisse nachzuvollziehen und darauf aufzubauen. Ob und wie die Daten geteilt werden können, hängt von der Sensitivität und dem Volumen der Daten ab. Das Teilen großer Datensätze kann kostenintensiv sein, was hier eventuell abschreckt. Wenn die Daten persönliche Informationen beinhalten, sodass die Data Privacy eine Rolle spielt, kann es notwendig sein, die Daten zu anonymisieren, oder auch komplett verboten sein, die Daten zu teilen. Ähnliches kann auch in einem industriellen Kontext mit internen Daten eines Unternehmens gelten. Wenn Daten geteilt werden, sollte dies den FAIR-Prinzipien genügen:
Findable: Die Daten müssen einfach zu finden sein, zum Beispiel durch einen Digital Object Identifier (DOI).
Accessible: Der Zugriff auf die Daten muss einfach sein.
Interoperable: Alle notwendigen Informationen zur Nutzung der Daten sollten bekannt sein.
Reusable: Die Daten sollten mit einer Lizenz versehen sein, die die Wiederverwendung erlaubt, und entsprechend den in einer Community geltenden Standards geteilt werden.