
10. Text Mining#
Beim Text Mining geht es um die Anwendung der in den vergangenen Kapiteln besprochenen Methoden auf textuelle Daten mit dem Ziel, Wissen aus den Daten zu gewinnen. Beispiele für Text Mining sind die Analyse von Kundenbewertungen bezüglich der Emotion und Meinung (engl. sentiment) oder die automatische Gruppierung ähnlicher Dokumente. Das Problem bei der Analyse von natürlicher Sprache ist, dass Sätze und längere Texte weder numerisch noch kategorisch sind. Es gibt also keine offensichtliche Darstellung durch Merkmale. Hinzu kommt, dass Text oft eine innere Struktur hat, zum Beispiel durch Überschriften, Einleitungen oder Referenzen zu verwandten Inhalten. Wenn wir Text lesen, erkennen wir diese semantische Struktur automatisch und ordnen diese ein. Daher ist es die große Herausforderung des Text Mining, eine geeignete Struktur der textuellen Daten für das maschinelle Lernen zu finden.
Hierfür müssen wir den Text codieren, um eine numerische oder kategorische Repräsentation zu erhalten. Ziel der Repräsentation sollte sein, möglichst wenig relevante Information aus dem Text zu verlieren. Eine ideale Codierung beinhaltet daher nicht nur die Worte, sondern auch die Bedeutung der Worte im jeweiligen Kontext, die grammatikalische Struktur und eventuell sogar den Gesamtkontext eines Satzes innerhalb eines Dokuments. Aufgrund dieser Komplexität ist die Repräsentation von Texten für das maschinelle Lernen immer noch der Gegenstand der aktuellen Forschung. Durch Fortschritte der letzten Jahre wird das Text Mining jedoch zu einem immer mächtigeren und zuverlässigeren Werkzeug. Das Text Mining selbst ist ein großes Gebiet, bei dem wir hier nur an der Oberfläche kratzen können. Das Ziel dieses Kapitels ist es, dass wir ein gutes Verständnis der Herausforderungen vom Text Mining bekommen, grundlegende Verfahren kennenlernen und außerdem Wissen wie fortgeschrittene Verfahren erarbeiten.
Als Beispiel nutzen wir in diesem Kapitel acht Tweets von Donald Trump. Die Verarbeitungsschritte, die wir zeigen, haben alle das Ziel, die Analyse des Themas der Tweets zu erlauben. Ähnlich wie bei den Bostondaten ist es auch bei Donald Trumps Tweets: Diese sind inhaltlich, vor allem was das Thema Wahlen angeht, nicht unproblematisch. Problematische Daten existieren aber und es ist wichtig, sich auch damit auseinanderzusetzen. Hinzu kommt, dass sie ein gutes Beispiel sind, um zu zeigen, wie Text Mining funktioniert: Sie sind kurz, jeder kennt das Medium, die Auswahl an Tweets ist inhaltlich unkritisch und die Daten beinhalten die üblichen Probleme, auf die man beim Text Mining trifft.
Show code cell source
from textwrap import TextWrapper
tweets_list = ['Oct 4, 2018 08:03:25 PM Beautiful evening in Rochester, Minnesota. VOTE, VOTE, VOTE! https://t.co/SyxrxvTpZE [Twitter for iPhone]',
'Oct 4, 2018 07:52:20 PM Thank you Minnesota - I love you! https://t.co/eQC2NqdIil [Twitter for iPhone]',
'Oct 4, 2018 05:58:21 PM Just made my second stop in Minnesota for a MAKE AMERICA GREAT AGAIN rally. We need to elect @KarinHousley to the U.S. Senate, and we need the strong leadership of @TomEmmer, @Jason2CD, @JimHagedornMN and @PeteStauber in the U.S. House! [Twitter for iPhone]',
'Oct 4, 2018 05:17:48 PM Congressman Bishop is doing a GREAT job! He helped pass tax reform which lowered taxes for EVERYONE! Nancy Pelosi is spending hundreds of thousands of dollars on his opponent because they both support a liberal agenda of higher taxes and wasteful spending! [Twitter for iPhone]',
'Oct 4, 2018 02:29:27 PM "U.S. Stocks Widen Global Lead" https://t.co/Snhv08ulcO [Twitter for iPhone]',
'Oct 4, 2018 02:17:28 PM Statement on National Strategy for Counterterrorism: https://t.co/ajFBg9Elsj https://t.co/Qr56ycjMAV [Twitter for iPhone]',
'Oct 4, 2018 12:38:08 PM Working hard, thank you! https://t.co/6HQVaEXH0I [Twitter for iPhone]',
'Oct 4, 2018 09:17:01 AM This is now the 7th. time the FBI has investigated Judge Kavanaugh. If we made it 100, it would still not be good enough for the Obstructionist Democrats. [Twitter for iPhone]']
wrapper = TextWrapper(width=65)
for tweet in tweets_list:
print('\n'.join(wrapper.wrap(tweet)))
print()
Oct 4, 2018 08:03:25 PM Beautiful evening in Rochester,
Minnesota. VOTE, VOTE, VOTE! https://t.co/SyxrxvTpZE [Twitter for
iPhone]
Oct 4, 2018 07:52:20 PM Thank you Minnesota - I love you!
https://t.co/eQC2NqdIil [Twitter for iPhone]
Oct 4, 2018 05:58:21 PM Just made my second stop in Minnesota for
a MAKE AMERICA GREAT AGAIN rally. We need to elect @KarinHousley
to the U.S. Senate, and we need the strong leadership of
@TomEmmer, @Jason2CD, @JimHagedornMN and @PeteStauber in the U.S.
House! [Twitter for iPhone]
Oct 4, 2018 05:17:48 PM Congressman Bishop is doing a GREAT job!
He helped pass tax reform which lowered taxes for EVERYONE! Nancy
Pelosi is spending hundreds of thousands of dollars on his
opponent because they both support a liberal agenda of higher
taxes and wasteful spending! [Twitter for iPhone]
Oct 4, 2018 02:29:27 PM "U.S. Stocks Widen Global Lead"
https://t.co/Snhv08ulcO [Twitter for iPhone]
Oct 4, 2018 02:17:28 PM Statement on National Strategy for
Counterterrorism: https://t.co/ajFBg9Elsj https://t.co/Qr56ycjMAV
[Twitter for iPhone]
Oct 4, 2018 12:38:08 PM Working hard, thank you!
https://t.co/6HQVaEXH0I [Twitter for iPhone]
Oct 4, 2018 09:17:01 AM This is now the 7th. time the FBI has
investigated Judge Kavanaugh. If we made it 100, it would still
not be good enough for the Obstructionist Democrats. [Twitter for
iPhone]
10.1. Preprocessing#
Durch das Preprocessing wird der Text in eine Repräsentation überführt, die für maschinelles Lernen geeignet ist, also mit der man den Text klassifizieren oder clustern kann.
10.1.1. Erstellung eines Korpus#
Der erste Preprocessing-Schritt ist die Erstellung eines Korpus von Dokumenten. Im Sinne der in Kapitel 3 eingeführten Begriffe sind die Dokumente die Objekte und ein Korpus eine Menge von Objekten. In unserem Twitter-Beispiel ist der Korpus eine Menge von Tweets, jeder Tweet ist ein Dokument. Wir haben bereits eine Liste von Tweets, was einem Korpus entspricht. In anderen Anwendungsfäl-len kann die Erstellung des Korpus aufwendiger sein. Dies wäre zum Beispiel der Fall, wenn erst Bewertungen eines Produkts durch Crawling aus dem Internet gesammelt werden müssen. Hierbei ist es relativ wahrscheinlich, dass es auf der gleichen Webseite mehrere Bewertungen gibt. Diese müssen dann zum Beispiel innerhalb der Webseite identifiziert und anschließend in separate Dokumente aufgeteilt werden.
10.1.2. Relevanter Inhalt#
Die textuellen Daten beinhalten oft irrelevante Informationen für einen bestimmten Anwendungsfall, insbesondere wenn der Text automatisch aus dem Internet gesammelt wurde. Wenn wir am Thema von Tweets interessiert sind, ist der Zeitstempel irrelevant. Es ist ebenfalls nicht wichtig, ob ein Tweet mit einem iPhone oder einer anderen Anwendung verschickt wurde. Links zu Webseiten sind knifflig, da sie relevante Informationen enthalten könnten, jedoch auch irrelevant sein können. Wenn eine URL relevante Informationen, wie zum Beispiel den Autor oder das Thema, enthält, kann dies wertvoll für das Text Mining sein. Andere Aspekte, wie zum Beispiel das http(s):// zu Beginn eines Links, sind irrelevant. Es gibt auch Links, die keine relevanten Informationen enthalten, zum Beispiel wenn Link Shortener benutzt werden. Dann ist der Link nur eine zufällige Zeichenkette. Ob Links beibehalten werden sollen, muss man daher von Anwendungsfall zu Anwendungsfall entscheiden.
Wenn wir den irrelevanten Inhalt der Tweets (inkl. Links) entfernen, bekommen wir Folgendes:
Show code cell source
import re
tweets_relevant_content = []
for tweet in tweets_list:
# remove the first 24 chars, because they are the time stamp
# remove everything after last [ because this is the source of the tweet
modified_tweet = tweet[24:tweet.rfind('[')]
# drop links
modified_tweet = re.sub(r'http\S+', '', modified_tweet).strip()
tweets_relevant_content.append(modified_tweet)
for tweet in tweets_relevant_content:
print('\n'.join(wrapper.wrap(tweet)))
print()
Beautiful evening in Rochester, Minnesota. VOTE, VOTE, VOTE!
Thank you Minnesota - I love you!
Just made my second stop in Minnesota for a MAKE AMERICA GREAT
AGAIN rally. We need to elect @KarinHousley to the U.S. Senate,
and we need the strong leadership of @TomEmmer, @Jason2CD,
@JimHagedornMN and @PeteStauber in the U.S. House!
Congressman Bishop is doing a GREAT job! He helped pass tax
reform which lowered taxes for EVERYONE! Nancy Pelosi is spending
hundreds of thousands of dollars on his opponent because they
both support a liberal agenda of higher taxes and wasteful
spending!
"U.S. Stocks Widen Global Lead"
Statement on National Strategy for Counterterrorism:
Working hard, thank you!
This is now the 7th. time the FBI has investigated Judge
Kavanaugh. If we made it 100, it would still not be good enough
for the Obstructionist Democrats.
Was relevant und irrelevant ist, hängt auch vom Kontext ab. Ein anderer Anwendungsfall für unsere Twitterdaten wäre die Analyse der Quelle der Tweets, um zum Beispiel herauszufinden, ob es einen Unterschied macht, ob ein Tweet von einem Handy oder von einem Computer verschickt wurde. In diesem Fall kann man die Quelle nicht einfach entfernen, da man sie zur Gruppierung der Tweets braucht. Wenn man wissen möchte, wie sich Tweets im Laufe der Zeit verändern, dann sind die Zeitstempel wichtig. In beiden Fällen würde man aber diese Informationen trotzdem aus dem eigentlichen Text entfernen und sie stattdessen als separate Merkmale speichern, da es sich um Metadaten über die Dokumente handelt.
10.1.3. Zeichensetzung und Großschreibung#
Für das Thema von Dokumenten sind die Zeichensetzung und die Groß- und Kleinschreibung von Buchstaben in der Regel irrelevant. Stattdessen führen sie dazu, dass es ungewollte Unterschiede zwischen Worten gibt. Eine Ausnahme von dieser Regel bilden Abkürzungen und Akronyme. Das Akronym U.S. der Tweets ist ein perfektes Beispiel hierfür, da es zum Wort us werden würde, wenn man einfach alle Zeichen entfernen und alle Buchstaben zu Kleinbuchstaben umwandeln würde. Wir würden also eine ganz andere Bedeutung erhalten. Wenn solche Fälle bekannt sind, sollte man diese manuell adressieren, bevor die Zeichensetzung und Großschreibung entfernt wird. Man könnte zum Beispiel US und U.S. zu usa umwandeln, um zu verhindern, dass es ein Problem gibt.
Wenn wir dies bei den Tweets anwenden, bekommen wir folgende Dokumente:
Show code cell source
import string
tweets_lowercase = []
for tweet in tweets_relevant_content:
modified_tweet = tweet.translate(str.maketrans('', '', string.punctuation))
modified_tweet = modified_tweet.replace('US', 'usa')
modified_tweet = modified_tweet.lower()
tweets_lowercase.append(modified_tweet)
for tweet in tweets_lowercase:
print('\n'.join(wrapper.wrap(tweet)))
print()
beautiful evening in rochester minnesota vote vote vote
thank you minnesota i love you
just made my second stop in minnesota for a make america great
again rally we need to elect karinhousley to the usa senate and
we need the strong leadership of tomemmer jason2cd jimhagedornmn
and petestauber in the usa house
congressman bishop is doing a great job he helped pass tax reform
which lowered taxes for everyone nancy pelosi is spending
hundreds of thousands of dollars on his opponent because they
both support a liberal agenda of higher taxes and wasteful
spending
usa stocks widen global lead
statement on national strategy for counterterrorism
working hard thank you
this is now the 7th time the fbi has investigated judge kavanaugh
if we made it 100 it would still not be good enough for the
obstructionist democrats
10.1.4. Stoppwörter#
Eine weitere Eigenschaft von Text ist, dass nicht jedes Wort relevant für die Bedeutung ist. Oft werden Wörter nur für die korrekte grammatikalische Struktur benötigt, ohne dass sie die Bedeutung eines Dokuments beeinflussen. Beispiele dafür sind Artikel (der, die, das, den, dem bzw. auf Englisch the, a). Außerdem gibt es noch Wörter, die sehr häufig vorkommen, unabhängig vom Inhalt, zum Beispiel die verschiedenen Formen von sein und haben. Daher besteht ein üblicher Preprocessing-Schritt darin, solche Wörter zu entfernen. Hierzu nutzt man Wortlisten, die es für viele Sprachen als Teil von Textverarbeitungsbibliotheken gibt.
Mit einer englischen Stoppwortliste verändern sich unsere Tweets wie folgt:
Show code cell source
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# this needs only to be run once
# uncomment this line to download the stopword and punctuation lists
# import nltk; nltk.download('stopwords'); nltk.download('punkt')
stop_words = set(stopwords.words('english'))
tweets_no_stopwords = []
for tweet in tweets_lowercase:
tweet_tokens = word_tokenize(tweet)
modified_tweet = ' '.join([w for w in tweet_tokens if not w in stop_words])
tweets_no_stopwords.append(modified_tweet)
for tweet in tweets_no_stopwords:
print('\n'.join(wrapper.wrap(tweet)))
print()
beautiful evening rochester minnesota vote vote vote
thank minnesota love
made second stop minnesota make america great rally need elect
karinhousley usa senate need strong leadership tomemmer jason2cd
jimhagedornmn petestauber usa house
congressman bishop great job helped pass tax reform lowered taxes
everyone nancy pelosi spending hundreds thousands dollars
opponent support liberal agenda higher taxes wasteful spending
usa stocks widen global lead
statement national strategy counterterrorism
working hard thank
7th time fbi investigated judge kavanaugh made 100 would still
good enough obstructionist democrats
10.1.5. Stemming und Lemmatisierung#
Für die gleiche Grundform gibt es oft viele grammatikalische Formen (z.B. Singular und Plural), was zu verschiedenen Schreibweisen führt. Außerdem gibt es verwandte Verben, Adjektive und Nomen. Hinzu kommen Synonyme, also mehrere Wörter mit der gleichen Bedeutung. Für das Text Mining ist es wichtig, zu erkennen, dass es sich eigentlich um die gleiche Bedeutung handelt. Ein Ansatz besteht darin, dass man versucht, alle Wörter auf ein gemeinsames Merkmal abzubilden. Stemming und Lemmatisierung sind zwei Methoden, mit denen man dies erreichen kann.
Beim Stemming werden Wörter auf ihren Stamm reduziert. Aus dem deutschen lachte und lachen wird lach, aus dem englischen spending und spends wird spend. Für das Stemming wird in der Regel ein algorithmischer Ansatz verwendet, zum Beispiel Porters Algorithmus [1]. Der Nachteil beim Stemming ist, dass man Wörter nur auf ihren Stamm reduzieren kann. Ähnliche Wörter mit einem anderen Stamm werden nicht vereinheitlicht, zum Beispiel gewinnen und gewann oder good und well.
Bei der Lemmatisierung wird mit Wortlisten gearbeitet. Diese Wortlisten definieren, welche Wörter als Synonyme behandelt werden sollen. Anschließend kann man eines der Synonyme auswählen. Auf diese Weise könnte man zum Beispiel alle Formen von good erkennen, insbesondere auch Formen wie well, die nicht den gleichen Wortstamm haben. Die Lemmatisierung ist jedoch nur so mächtig, wie es die Wortlisten zulassen.
Wenn man sowohl Lemmatisierung als auch Stemming anwenden möchte, sollte man immer zuerst Lemmatisieren. Der Grund liegt darin, dass die durch das Stemming gefundenen Wortstämme nicht immer Wörter sind, die es in der natürlichen Sprache gibt. Entsprechend gibt es auch keine Einträge in den Wortlisten für das Lemmatisieren. Man reduziert also die Mächtigkeit der Lemmatisierung, wenn man zuerst Stemming anwendet.
Für unsere Tweets verwenden wir zuerst eine Lemmatisierung mit einer englischen Wortliste.
Show code cell source
# The following two lines must be run once in each environment
# This downloads the list from nltk for lemmatization
# import nltk; nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
# the wordnet lemmatizer does not only harmonize synonyms but also performs some stemming
lemmatizer = WordNetLemmatizer()
tweets_lemmatization = []
for tweet in tweets_no_stopwords:
tweet_tokens = word_tokenize(tweet)
modified_tweet = ' '.join([lemmatizer.lemmatize(w) for w in tweet_tokens])
tweets_lemmatization.append(modified_tweet)
for tweet in tweets_lemmatization:
print('\n'.join(wrapper.wrap(tweet)))
print()
beautiful evening rochester minnesota vote vote vote
thank minnesota love
made second stop minnesota make america great rally need elect
karinhousley usa senate need strong leadership tomemmer jason2cd
jimhagedornmn petestauber usa house
congressman bishop great job helped pas tax reform lowered tax
everyone nancy pelosi spending hundred thousand dollar opponent
support liberal agenda higher tax wasteful spending
usa stock widen global lead
statement national strategy counterterrorism
working hard thank
7th time fbi investigated judge kavanaugh made 100 would still
good enough obstructionist democrat
Einige Wörter wurden ersetzt, aus stocks wurde zum Beispiel stock. Mit Stemming erhalten wir folgende Veränderungen:
Show code cell source
from nltk.stem import PorterStemmer
# porter stemming is a linguistic algorithm that provides additional stemming
stemmer = PorterStemmer()
tweets_stemming = []
for tweet in tweets_lemmatization:
tweet_tokens = word_tokenize(tweet)
modified_tweet = ' '.join([stemmer.stem(w) for w in tweet_tokens])
tweets_stemming.append(modified_tweet)
for tweet in tweets_stemming:
print('\n'.join(wrapper.wrap(tweet)))
print()
beauti even rochest minnesota vote vote vote
thank minnesota love
made second stop minnesota make america great ralli need elect
karinhousley usa senat need strong leadership tomemm jason2cd
jimhagedornmn petestaub usa hous
congressman bishop great job help pa tax reform lower tax everyon
nanci pelosi spend hundr thousand dollar oppon support liber
agenda higher tax wast spend
usa stock widen global lead
statement nation strategi counterterror
work hard thank
7th time fbi investig judg kavanaugh made 100 would still good
enough obstructionist democrat
Viele der Wörter sind jetzt kürzer, unter anderem wurde hundred auf hundr, wasteful auf wast und spending auf spend reduziert. Zwei dieser Beispiele sind keine echten Wörter mehr, da die Wortstämme hundr und wast nicht in der englischen Sprache vorkommen.
10.1.6. Visualisierung des Preprocessings#
Eine einfache Möglichkeit, textuelle Daten zu visualisieren, sind Wortwolken (engl. word clouds). Wortwolken zeigen wichtige Wörter, die in Texten häufig vorkommen. Je häufiger ein Wort vorkommt, desto größer wird es dargestellt. Mithilfe von Wortwolken können wir uns gut die Auswirkungen der Preprocessing-Schritte auf unsere Tweets veranschaulichen.
Show code cell source
import matplotlib.pyplot as plt
from wordcloud import WordCloud
wc_raw = WordCloud(background_color="white")
wc_raw.generate(' '.join(tweets_list))
wc_relevant = WordCloud(background_color="white")
wc_relevant.generate(' '.join(tweets_relevant_content))
wc_lowercase = WordCloud(background_color="white")
wc_lowercase.generate(' '.join(tweets_lowercase))
wc_stopwords = WordCloud(background_color="white")
wc_stopwords.generate(' '.join(tweets_no_stopwords))
wc_lemma = WordCloud(background_color="white")
wc_lemma.generate(' '.join(tweets_lemmatization))
wc_stemming = WordCloud(background_color="white")
wc_stemming.generate(' '.join(tweets_stemming))
fig, axes = plt.subplots(3, 2, figsize=(12, 11))
axes[0, 0].axis("off")
axes[0, 0].imshow(wc_raw, interpolation="bilinear")
axes[0, 0].set_title('Kein Preprocessing')
axes[0, 1].axis("off")
axes[0, 1].imshow(wc_relevant, interpolation="bilinear")
axes[0, 1].set_title('Relevanter Inhalt')
axes[1, 0].axis("off")
axes[1, 0].imshow(wc_lowercase, interpolation="bilinear")
axes[1, 0].set_title('Kleinschreibung und keine Satzzeichen')
axes[1, 1].axis("off")
axes[1, 1].imshow(wc_stopwords, interpolation="bilinear")
axes[1, 1].set_title('Stopwords entfernt')
axes[2, 0].axis("off")
axes[2, 0].imshow(wc_lemma, interpolation="bilinear")
axes[2, 0].set_title('Mit Lemmatisierung')
axes[2, 1].axis("off")
axes[2, 1].imshow(wc_stemming, interpolation="bilinear")
axes[2, 1].set_title('Mit Stemming')
plt.show()
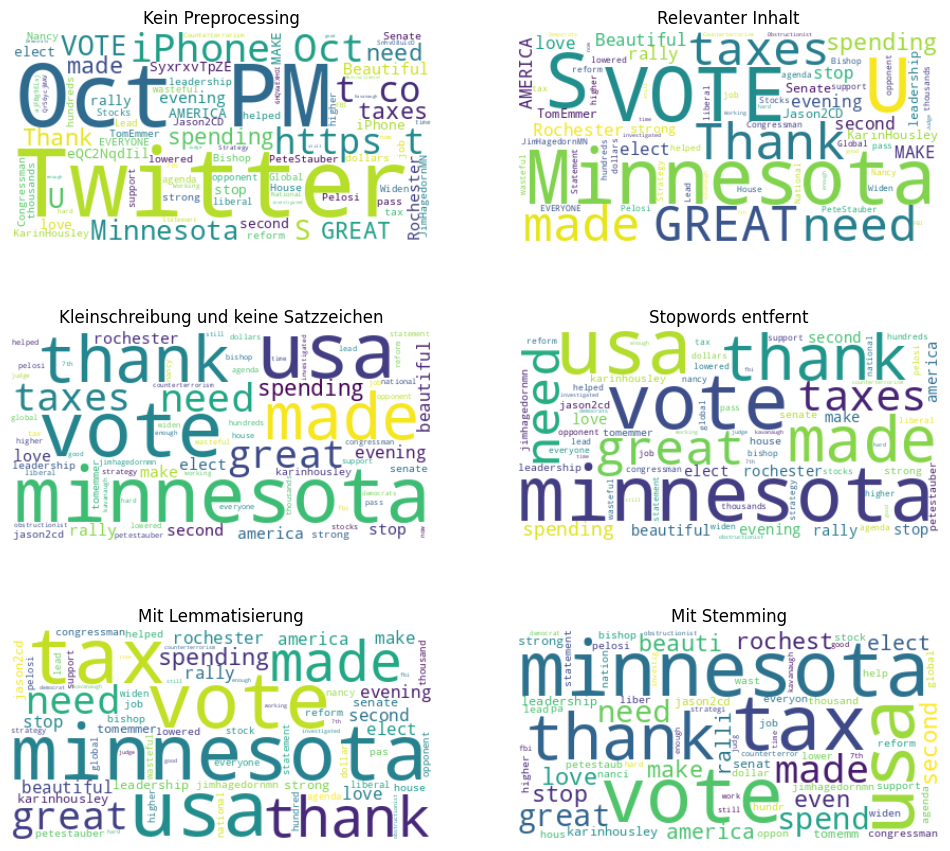
10.1.7. Bag-of-Words#
Nach dem Preprocessing können wir eine numerische Repräsentation namens Bag-of-Words erstellen. Ein Bag-of-Words ist ähnlich zu einem One-Hot Encoding für Text. Jedes Wort ist ein Merkmal. Der Wert des Merkmals ist die Häufigkeit des Worts im Dokument. Die Worthäufigkeit wird in diesem Kontext auch als Term Frequency (TF) bezeichnet. Hier zeigt sich auch, warum die Harmonisierung sinnvoll ist: Ähnliche Wörter, die zur gleichen Repräsentation harmonisiert wurden, zählen zur Häufigkeit des gleichen Merkmals. Ein Bag-of-Words für unsere Tweets sieht wie folgt aus.
Show code cell source
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
bag_of_words = vectorizer.fit_transform(tweets_stemming)
# from scikit-learn 1.0 onwards, we need to use get_feature_names_out instead of get_feature_names
bag_of_words_df = pd.DataFrame(bag_of_words.todense(), columns=vectorizer.get_feature_names_out())
bag_of_words_df
| 100 | 7th | agenda | america | beauti | bishop | congressman | counterterror | democrat | dollar | ... | thank | thousand | time | tomemm | usa | vote | wast | widen | work | would | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 7 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
8 rows × 70 columns
Den Bag-of-Words kann man als Eingabe für Algorithmen nutzen. Beim Clustering würde man Dokumente, die die gleichen Wörter benutzen, gemeinsam gruppieren, bei der Klassifikation würde man Scores und Klassen basierend auf den Worthäufigkeiten berechnen.
10.1.8. Inverse Document Frequency#
Eine beliebte Erweiterung des Bag-of-Words ist die Inverse Document Frequency (IDF). Hinter der IDF steckt die Idee, dass man die Wörter nach ihrer “Einzigartigkeit” gewichten sollte. Wenn ein Wort in nur wenigen Dokumenten vorkommt, könnte es sehr spezifisch sein und sollte daher einen größeren Einfluss haben. Wenn ein Wort in sehr vielen Dokumenten vorkommt, ist es eher unspezifisch und sollte daher nur geringen Einfluss haben. Diese Idee ist ähnlich zur Entfernung von Stoppwörtern, nur dass mit Gewichten gearbeitet wird und keine Begriffe komplett entfernt werden. Die IDF ist definiert als
wobei \(t\) ein Wort (Term) ist, \(N\) die Anzahl der Dokumente im Korpus und \(D_t\) die Anzahl der Dokumente, die \(t\) enthält. Die TF-IDF kombiniert die Term Frequency mit den Gewichten der IDF und kann anstatt der TF im Bag-of-Words benutzt werden. TF-IDF ist für ein Wort \(t\) definiert als
Mit unseren Tweets erhalten wir einen Bag-of-Words mit folgenden TF-IDF-Werten:
Show code cell source
import numpy as np
bag_of_words_df.apply(lambda col: col*np.log(len(col)/col.gt(0).sum()))
| 100 | 7th | agenda | america | beauti | bishop | congressman | counterterror | democrat | dollar | ... | thank | thousand | time | tomemm | usa | vote | wast | widen | work | would | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 6.238325 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 1.386294 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 2.772589 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 3 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 2.079442 | 2.079442 | 0.000000 | 0.000000 | 2.079442 | ... | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 0.000000 |
| 4 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.386294 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 |
| 5 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 6 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 1.386294 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 |
| 7 | 2.079442 | 2.079442 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 | 0.000000 | ... | 0.000000 | 0.000000 | 2.079442 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 2.079442 |
8 rows × 70 columns
Bemerkung:
Die IDF wird oft mit einer Glättung als \(IDF_t = \log\frac{N}{D_t+1}\) definiert. Hierdurch werden undefinierte Werte durch einen Logarithmus von 0 vermieden, wenn ein Wort nicht in einem Korpus auftaucht. Es gibt noch andere ähnliche Glättungen. Diese Glättung hat in der Regel keinen Einfluss auf die Ergebnisse, verhindert jedoch oft Schwierigkeiten, indem die numerische Stabilität erhöht wird.
10.1.9. Jenseits des Bag-of-Words#
Der Bag-of-Words ist eine gute Repräsentation, die sehr gut auch bei großen Datenmengen skaliert. Mit dieser relativ einfachen Repräsentation von Text sind jedoch auch diverse Nachteile verbunden. Zum einen werden alle strukturellen Aspekte von Text ignoriert, zum Beispiel die Grammatik. Zum anderen werden Ähnlichkeiten nicht berücksichtigt. Die Worte dollar und euro sind, basierend auf dem Bag-of-Words, genauso verschieden voneinander wie elefant und computer. Hierdurch ist es schwierig, einen abstrakteren Kontext zu lernen, zum Beispiel, dass etwas mit einer Währung zusammenhängt. Aus diesem Grund sind Bag-of-Words im modernen Text Mining eher als Einstieg zu verstehen, der für einfache Anwendungsfälle genügt, aber bei komplexen Anwendungsfällen oft nicht ausreichend ist. Eine relativ einfache Erweiterung sind \(n\)-grams, bei denen nicht individuelle Wörter, sondern Sequenzen aus \(n\) Wörtern als Merkmale verwendet werden. Hierdurch wird der Kontext zu einem gewissen Grad erfasst. Da es aber sehr viele Kombinationen von Wörtern gibt, skalieren \(n\)-grams nur sehr schlecht.
Neuere Text-Mining-Verfahren basieren daher auf neuronalen Netzen. Zum einen gibt es Worteinbettungen (engl. word embeddings), bei denen Wörter als Vektoren in einem hochdimensionalen Raum dargestellt werden. Je näher sich zwei Wörter in dieser Worteinbettung sind, desto ähnlicher sind die Wörter. Worteinbettungen selbst kann man ähnlich zu den Wortlisten, die uns oben begegnet sind, häufig direkt herunterladen und anwenden. Alternativ kann man für einen Text eigene Einbettungen mit einem einfachen neuronalen Netz lernen. Die neuesten Text-Mining-Verfahren basieren auf tiefen neuronalen Netzen mit einer sogenannten Transformer-Architektur. Derartige neuronale Netze betrachten nicht nur einzelne Wörter, sondern den kompletten Kontext eines Textes. Wie sich der Kontext von Wörtern zusammensetzt, wird aus riesigen Datenmengen gelernt, um dies in Anwendungen ausnutzen zu können.
10.2. Herausforderungen des Text Mining#
Auch wenn es mittlerweile gute Repräsentationen für Text gibt, sind viele Herausforderungen des Text Mining immer noch ungelöst und manche auch gar nicht lösbar.
10.2.1. Dimensionalität#
Das erste Problem ist die Dimensionalität. In unserem Beispiel haben wir lediglich acht Tweets, aber trotzdem noch 70 verschiedene Wörter nach dem Preprocessing. In einem längeren Text gibt es häufig Tausende von Wörtern. Es gibt also sehr viele Merkmale. Hinzu kommt, dass der Korpus eventuell auch sehr viele Dokumente enthalten kann. Täglich gibt es zum Beispiel über 100 Millionen Tweets, die im Rahmen einer umfassenden Analyse von sozialen Netzwerken betrachtet werden müssten.
Die Kombination aus vielen Merkmalen und vielen Instanzen führt dazu, dass man für Text Mining häufig hohe Anforderungen an die Analyseumgebung stellt. Große Text-Mining-Projekte, insbesondere solche, die auf neuronalen Netzen basieren, benötigen daher spezielle Hardware. Dies ist auch ein Grund, warum ein einfacher Ansatz wie der Bag-of-Words immer noch hoch relevant ist: Mit einem Bag-of-Words und einem relativ einfachen Algorithmus wie Multinomial Naive Bayes kann man häufig auch auf einfacher Hardware bereits gute Ergebnisse erreichen.
10.2.2. Mehrdeutigkeiten#
Das zweite Problem ist die Mehrdeutigkeit der natürlichen Sprache. Teilweise ist dieses Problem nicht lösbar, da man häufig den Kontext benötigt, um den Inhalt zu verstehen. Der Kontext selbst besteht aber nicht nur aus dem Text, sondern auch aus den Aspekten rund um ein Dokument. Innerhalb dieses Buches ist der Kontext des Wortes “Lernen” zum Beispiel ein anderer als in einem Buch über Didaktik. Hier ist ein Beispiel für einen Satz, den man nur im Kontext versteht:
Ist das sicher genug? (Ist diese Erkenntnis gesichert?)
Ist das sicher genug? (Ist die Gefahr eines Unfalls gering?)
Es gibt viele Beispiele für derartige Probleme, die unweigerlich zu Rauschen beim Text Mining führen.
Häufig liegen diese Probleme schon direkt bei den Wörtern, die wir verwenden: Homonyme sind Wörter mit mehreren Bedeutungen. Das Wort “erfassen” kann zum Beispiel heißen, dass man etwas aufnimmt, aber auch dass man von einem Fahrzeug überfahren wurde. Um Homonyme korrekt zu verarbeiten, muss man sie in ihrem Kontext interpretieren, was insbesondere beim Bag-of-Words ein Problem ist.
10.2.3. Weitere Probleme#
Es gibt noch weitere Probleme, die wir hier aber nicht im Detail diskutieren:
Rechtschreibfehler führen zu unbekannten Wörtern und lassen sich häufig nicht automatisch korrigieren.
Sprache entwickelt sich weiter, insbesondere in Form von neuen Wörtern und Jugendsprache, aber auch durch domänenspezifische Fachbegriffe.
Beim Preprocessing kann es leicht passieren, Aspekte zu übersehen, zum Beispiel durch mangelhafte Wortlisten.
Das Lesen von Text selbst ist häufig bereits ein Problem, insbesondere wenn verschiedene Codierungen (ASCII, UNICODE) und Zeichensätze (Chinesisch, Japanisch, Koreanisch, Arabisch, Kyrillisch, Lateinisch, …) verwendet werden.
Das heißt auch, dass man bei Text-Mining-Anwendungen in der Regel kein perfektes Ergebnis bekommt, sondern nur immer weitere Probleme lösen kann. Deshalb ist es bei Text-Mining-Projekten besonders wichtig, klare Ziele zu formulieren und hierdurch sicherzustellen, dass ein Projekt auch wirklich beendet wird und nicht immer weitere Sonderfälle betrachtet werden.
10.3. Übung#
In dieser Übung wollen wir das Text Mining mit einem größeren Beispiel vertiefen. Hierzu verwenden wir eine Erweiterung der oben genannten Tweets: Statt nur acht Tweets betrachten wir den vollständigen Korpus der Tweets von Donald Trump aus dem Jahr 2017 [2].
10.3.1. Wortwolke ohne Preprocessing#
Laden Sie die Daten. Erstellen Sie eine Wortwolke ohne jegliches Preprocessing. Welche Probleme gibt es? Was erkennt man eventuell trotzdem bereits?
10.3.2. Wortwolke mit Preprocessing#
Wenden Sie die Preprocessing-Schritte, die wir diskutiert haben, an und erstellen Sie eine neue Wortwolke.
10.3.3. TF-IDF#
Die Wortwolken benutzen üblicherweise die Worthäufigkeiten. Berechnen Sie die TF-IDF und erstellen Sie neue Wortwolken basierend auf den auf diese Art gewichteten Worthäufigkeiten. Wie verändert sich das Ergebnis?